“All models are wrong, but some are useful” – George Box
El Plato Simple es el primer ejercicio de pronóstico para la primera vuelta. De entrada, tiene dos limitaciones importantes: no modela la determinación simultánea de la votación para todos los candidatos, ni el sesgo de respuesta de las encuestas.
La receta va en reversa. Primero el plato (los resultados), después los ingredientes (datos), luego la receta (modelo), y al final la preparación en la cocina (código). Los detalles se ponen más técnicos entre más se acerquen a la cocina.
Plato
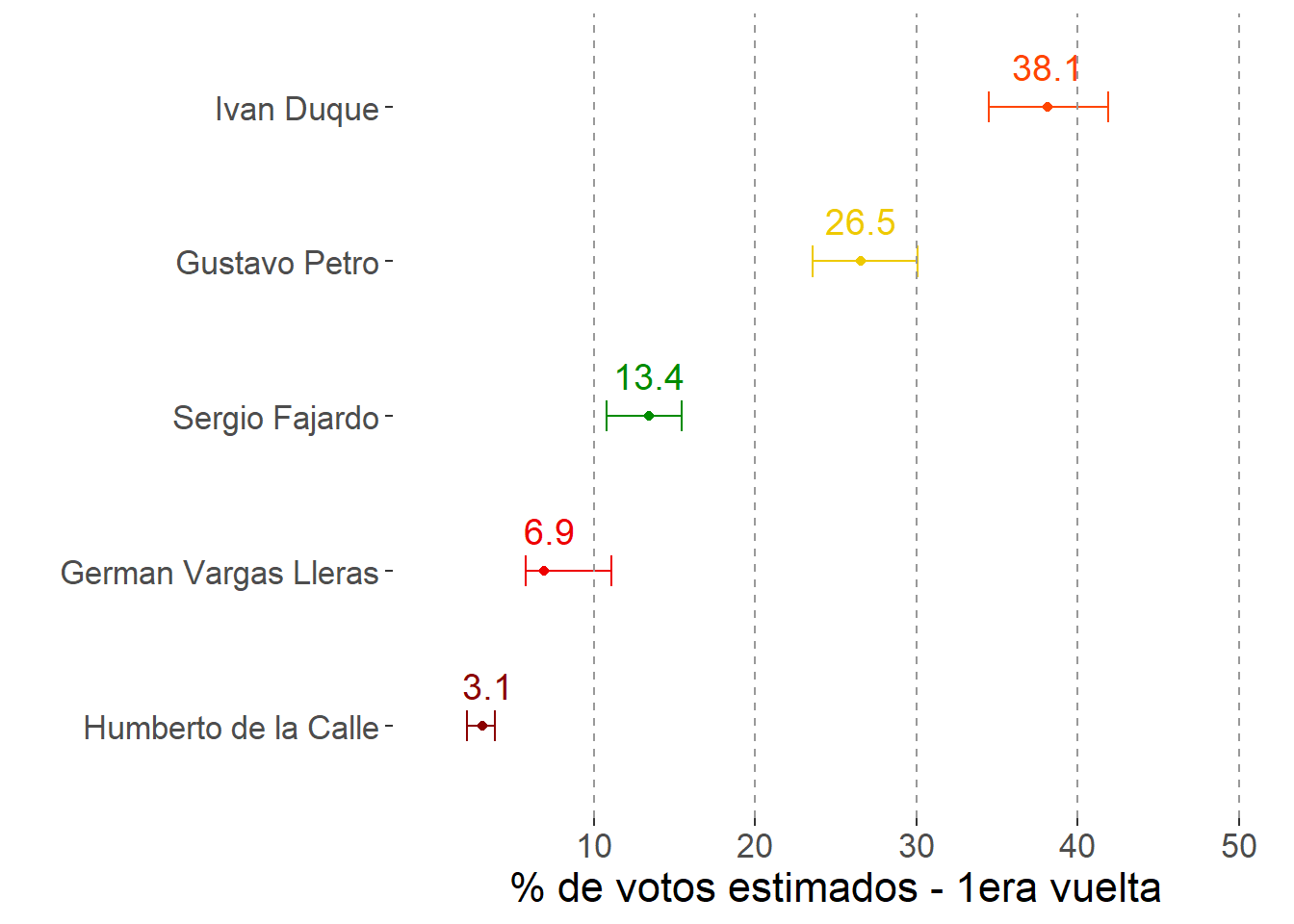
Los resultados del Plato Simple son promedios de la distribución posterior estimada para cada candidato, así como los intervalos HPD (higher posterior density) de 90% sobre cada parámetro. Para tener una referencia, el resultado se compara con un promedio simple de las 18 encuestas que se hicieron después de las elecciones legislativas del 11 de marzo.
Ver código
library(tidyverse)library(here)#Plato servidoreadr::read_csv(here("elecciones","2018-colombia","2018-04-17-simple-2018","simple-2018","simple_2018_resultados.csv"))%>%#Prediccionesdplyr::group_by(nombre)%>%dplyr::summarise(m_all =median(value), p10 =quantile(value,0.1), p90 =quantile(value,0.9))%>%dplyr::select(candidato=nombre,int_voto=m_all,int_voto_min=p10,int_voto_max=p90)%>%dplyr::mutate(candidato=factor(candidato,levels=c("Humberto de la Calle","German Vargas Lleras","Sergio Fajardo","Gustavo Petro","Ivan Duque")))%>%ggplot2::ggplot(ggplot2::aes(x=candidato, color=candidato))+#platoggplot2::geom_point(ggplot2::aes(y=int_voto))+ggplot2::geom_text(ggplot2::aes(y=int_voto,label=format(int_voto, digits=2)),vjust=-1, size=5)+ggplot2::geom_errorbar(ggplot2::aes(ymax=int_voto_max,ymin=int_voto_min,width=0.2))+ggplot2::geom_hline(yintercept=seq(10, 50, by =10), linetype="dashed",color="grey60")+#referenciasggplot2::geom_hline(yintercept=c(10,20,30,40,50),linetype="dashed",color="grey60")+ggplot2::coord_flip()+ggplot2::theme(legend.position="none", panel.background=ggplot2::element_rect(fill="white", color="white"), text =ggplot2::element_text(family ="News Cycle", size=16))+ggplot2::labs(x="",y="% de votos estimados - 1era vuelta")+ggplot2::scale_y_continuous(limits =c(0,50),breaks=c(10,20,30,40,50))+ggplot2::scale_color_manual(values=c("red4","red2","green4","gold2","orangered"))+ggplot2::scale_fill_manual(values=c("red4","red2","green4","gold2", "orangered"))
Resultados del Plato Simple
Ingredientes
El Plato Simple utiliza solo las encuestas y sus características. Antes de las consultas del 11 de marzo, y de la adhesión de Juan Carlos Pinzón a la campaña de German Vargas Lleras (el 16 de marzo de 2016), las encuestas estaban identificando un conjunto ruidoso de candidatos. Por esa razón, este modelo solo tiene en cuenta las encuestas realizadas después de las elecciones legislativas.
El modelo utiliza como priors para la estimación de un parámetro la proporción de votos promedio \(\mu_{candidato}\) y la desviación estándar \(\sigma_{candidato}\) que han registrado las encuestas para cada candidato. Los demás parámetros tienen priors poco informativos.
Ver código
library(tidyverse)library(kableExtra)library(lubridate)#1. Importar encuestas desde GitHub #### encuestas_ulr_2018<-"https://raw.githubusercontent.com/nelsonamayad/Elecciones-presidenciales-2018/master/Elecciones%202018/encuestas2018.csv"encuestas_2018<-readr::read_csv(encuestas_ulr_2018)# Preparar data frame para calcular priorsencuestas_2018%>%dplyr::select(n,fecha,ivan_duque,gustavo_petro,sergio_fajardo,german_vargas_lleras,humberto_delacalle)%>%dplyr::filter(dplyr::between(lubridate::as_date(fecha),lubridate::as_date("2018-03-11"),lubridate::as_date("2018-05-30")))%>%tidyr::pivot_longer(cols=c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras","humberto_delacalle"), names_to ="candidato", values_to ="int_voto")%>%dplyr::mutate(nombres =dplyr::case_when(candidato=="ivan_duque"~"Ivan Duque",candidato=="gustavo_petro"~"Gustavo Petro",candidato=="sergio_fajardo"~"Sergio Fajardo",candidato=="german_vargas_lleras"~"German Vargas Lleras",candidato=="humberto_delacalle"~"Humberto de la Calle"))%>%dplyr::group_by(nombres)%>%dplyr::mutate(prior_mu=mean(int_voto,na.rm=TRUE),prior_sigma=sd(int_voto,na.rm=TRUE))%>%dplyr::distinct(prior_mu,prior_sigma)%>%knitr::kable("html", digits=1,caption ="Priors por candidato", col.names =c("Candidato","$\\mu_{prior}$","$\\sigma_{prior}$"))%>%kableExtra::kable_styling(full_width =F)%>%kableExtra::row_spec(0,bold=TRUE, background ="#FF4900", color ="white")%>%kableExtra::footnote(number =c(paste0("Encuestas disponibles: 18")))
Priors por candidato
Candidato
\(\mu_{prior}\)
\(\sigma_{prior}\)
Ivan Duque
38.1
3.3
Gustavo Petro
26.8
3.4
Sergio Fajardo
13.1
2.9
German Vargas Lleras
7.5
2.1
Humberto de la Calle
3.0
1.1
1 Encuestas disponibles: 18
Priors Plato Simple
Receta
El modelo parte del supuesto de que la proporción de votos \(\pi\) que obtiene un candidato en las elecciones en el momento t es un reflejo de las preferencias que tiene la sociedad por ese candidato antes de las elecciones:
\[\pi_{candidato,t} \sim Normal(\pi_{candidato,t-1}, \sigma_{candidato,t-1})\] Como nadie es adivino para saber esas preferencias, solo se observan mediciones ruidosas de esa relación: las encuestas de intención de voto. Aunque no se puede conocer la proporción de votos que recibirá cada candidato antes del día de las elecciones, esa proporción es una función de la proporción de intención de voto \(\lambda\) que hayan capturado las encuestas que se hayan realizado antes de esa fecha.
\[\pi_{candidato,t-1} \sim Normal(\lambda_{candidato,t-1}, \sigma_{candidato,t-1})\] La proporción de votos para cada candidato se aproxima mediante un modelo lineal sobre las siguientes características de las encuestas: 1) el tamaño de la muestra de cada encuesta (m), 2) el márgen de error de la encuesta (e), 3) los días que pasaron entre la encuesta y la estimación (d), 4) una dummy para el tipo de encuesta (telefónica o presencial) (tipo). Además, se incluyen efectos aleatorios por encuestadora que permiten incorporar la variación a ese nivel.
Preparación
Este es el modelo completo, con los priors para cada parámetro. Los únicos priors informados son los que determinan el parámetro que captura el promedio y desviación estándar de cada candidato, y estos se actualizan con cada estimación del modelo cuando sale una nueva encuesta.
Hay que hacer unos cuantos ajustes a los datos de las encuestas antes de estimar el modelo:
Ver código
library(tidyverse)library(lubridate)# Alistamiento ####encuestas_simple_2018<-readr::read_csv("https://raw.githubusercontent.com/nelsonamayad/Elecciones-presidenciales-2018/master/Elecciones%202018/encuestas2018.csv")%>%# Seleccionar candidatos que encabezan las encuestasdplyr::select(n,fecha,encuestadora,ivan_duque,gustavo_petro,sergio_fajardo,german_vargas_lleras, humberto_delacalle, m_error=margen_error, muestra_int_voto,tipo)%>%# Pivotear los datostidyr::pivot_longer(cols =c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras", "humberto_delacalle"), names_to ="candidato", values_to ="int_voto")%>%# Seleccionar solo las encuestas hechas en 2018 antes de la primea vueltadplyr::filter(dplyr::between(as.Date(fecha, tz="GMT"),as.Date('2018-03-11', tz="GMT"),as.Date('2018-05-19', tz="GMT")))%>%# Crear algunas variablesdplyr::mutate(e_max =int_voto+m_error, e_min =int_voto-m_error, fecha =as.Date(fecha), candidato =factor(candidato, levels=c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras","humberto_delacalle")), enc =factor(encuestadora), encuestadora=as.numeric(enc))%>%#Crear variable duracion:dplyr::mutate(dd =as.Date(as.character(lubridate::today()), format="%Y-%m-%d")-as.Date(as.character(fecha), format="%Y-%m-%d"))%>%dplyr::mutate(dd =as.numeric(dd))%>%dplyr::mutate(dd =100*(dd/sum(dd)))%>%dplyr::mutate(tipo=ifelse(tipo=="Presencial",1,0))## Crear data frames por candidato: ####id_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="ivan_duque", !is.na(int_voto))gp_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="gustavo_petro", !is.na(int_voto))sf_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="sergio_fajardo", !is.na(int_voto))gvl_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="german_vargas_lleras", !is.na(int_voto))hdlc_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="humberto_delacalle", !is.na(int_voto))
Estimación
Este es el código para estimar el modelo para cada candidato. Solo se necesitan los datos cargados en R y tener el paquete RStan instalado (ver instrucciones acá)
El muestreo del modelo se hace en Stan, que para cada candidato utiliza su respectivo data frame y priors.
Por ejemplo, para el candidato Sergio Fajardo se utiliza el data frame sf y los priors \(\small\mu_{candidato}=13\) y \(\small\sigma_{candidato}=3\) en un objeto Stan de nombre fajardo.stan:
Ver código
data {int<lower=1> N;int<lower=1> N_encuestadora;vector[N] int_voto;array[N] int<lower=1, upper=N_encuestadora> encuestadora;vector[N] m_error;vector[N] tipo;vector[N] dd;// If this is truly an integer predictor, keep it as int; otherwise use vector[N].array[N] int muestra_int_voto;}parameters {real a1;vector[N_encuestadora] a_;real a_enc;real<lower=0> s_enc;real a2;real a3;real a4;real a5;real<lower=0> s;}transformed parameters {vector[N] m; m = a1 + a_[encuestadora] + a2 * to_vector(muestra_int_voto) + a3 * m_error + a4 * dd + a5 * tipo;}model {// priors s ~ cauchy(0, 5); s_enc ~ cauchy(0, 5); a1 ~ normal(13, 3); a_enc ~ normal(0, 10); a_ ~ normal(a_enc, s_enc); a2 ~ normal(0, 10); a3 ~ normal(0, 10); a4 ~ normal(0, 10); a5 ~ normal(0, 10);// likelihood int_voto ~ normal(m, s);}generated quantities {real dev; dev = -2 * normal_lpdf(int_voto | m, s);}
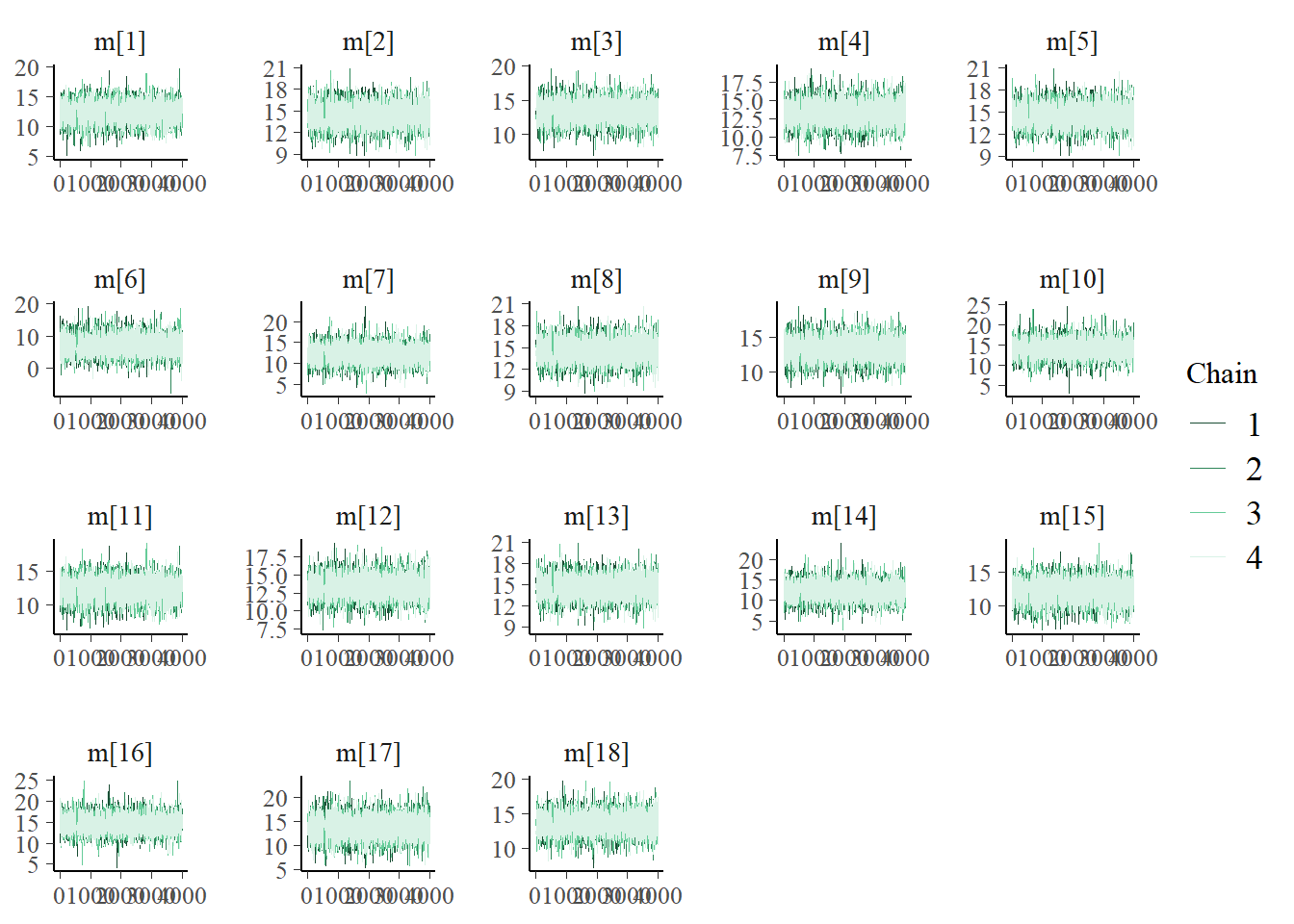
A pesar de las divergencias iniciales, el modelo converge rápido para todos los candidatos. Al fin y al cabo es muy simple y tiene pocas observaciones.
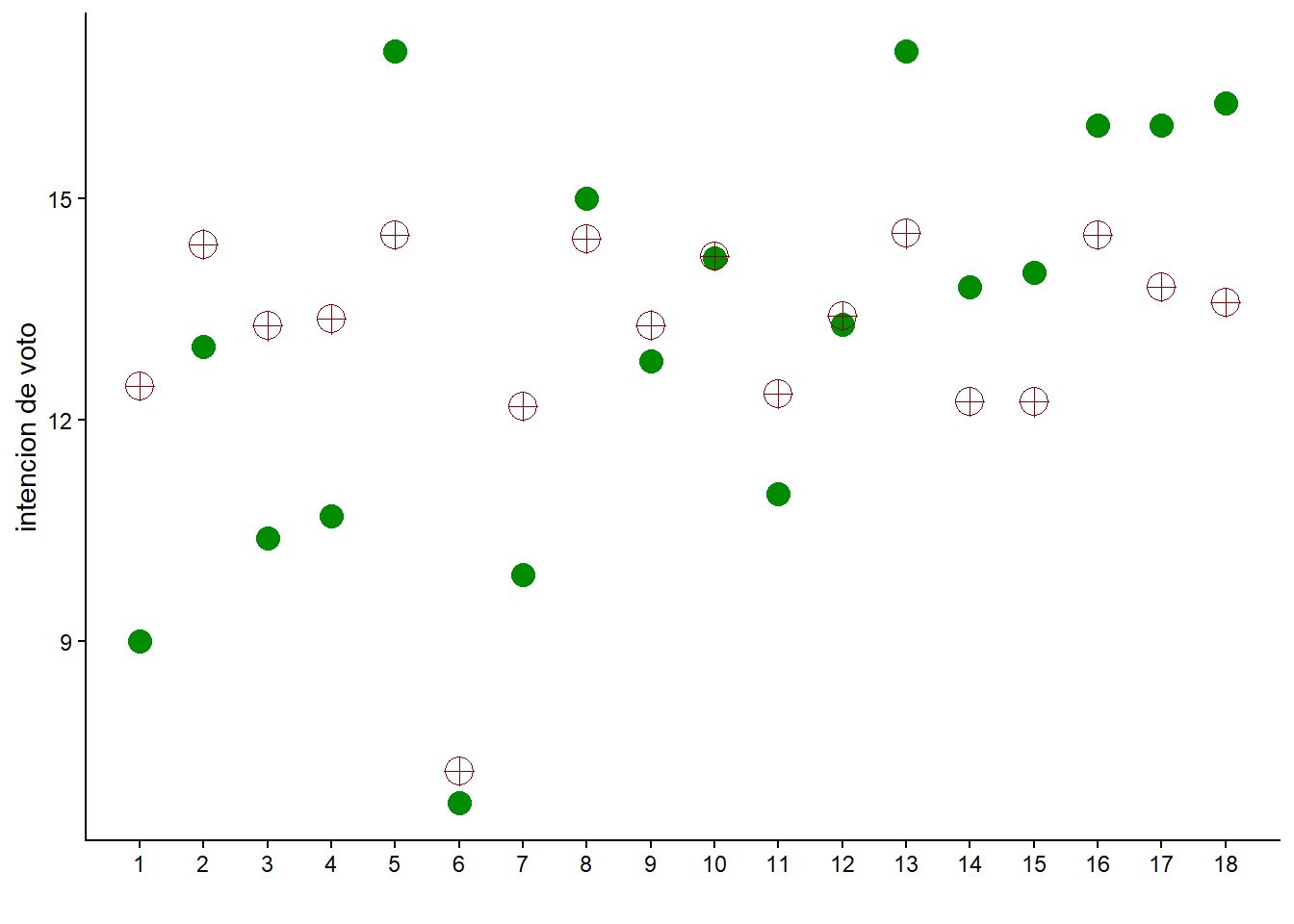
Por sugerencia de @infrahumano, incluyo dos gráficas antes de ir a shinystan: trace plot con bayesplot para ver cómo se comportaron las 4 cadenas en los parámetros clave, y una comparación a la carrera entre el promedio de cada parámetro y su valor observado.
Ver código
library(bayesplot)bayesplot::color_scheme_set("green")# Crear matriz de muestras de la distribucion posteriorposterior_fajardo<-posterior::as_draws_matrix(fajardo_fit)#Trace plot para los parametros de interesbayesplot::mcmc_trace(posterior_fajardo, pars=ggplot2::vars(tidyselect::starts_with("m[")))