El Ajiaco2 aumentado con tendencias y efectos de casas encuestadora
Autor/a
Afiliación
Recetas Electorales
Análisis independiente
Fecha de publicación
13 de abril de 2026
Fecha de última modificación
19 de mayo de 2026
“Don’t ask why you should use a multilevel model. Ask instead, Why not?.” –Richard McElreath
Introduciendo la Cazuela
La Cazuela es una extensión del Ajiaco2 que incorpora covariables al modelo Dirichlet-Multinomial, de manera similar a un modelo lineal generalizado (GLM). Mientras que el Ajiaco2 estima una sola proporción pooled \(\mathbf{p}\) común a todas las encuestas, la Cazuela permite que las proporciones varíen en función de:
Tendencia temporal: ¿Cómo ha cambiado el apoyo a cada candidato a lo largo del tiempo?
Efecto casa encuestadora: ¿Cada encuestadora tiene un sesgo sistemático hacia o en contra de ciertos candidatos?
El resultado es un modelo que no solo estima el estado actual de las preferencias electorales sino que también captura la dinámica temporal y corrige por las diferencias sistemáticas entre encuestadoras.
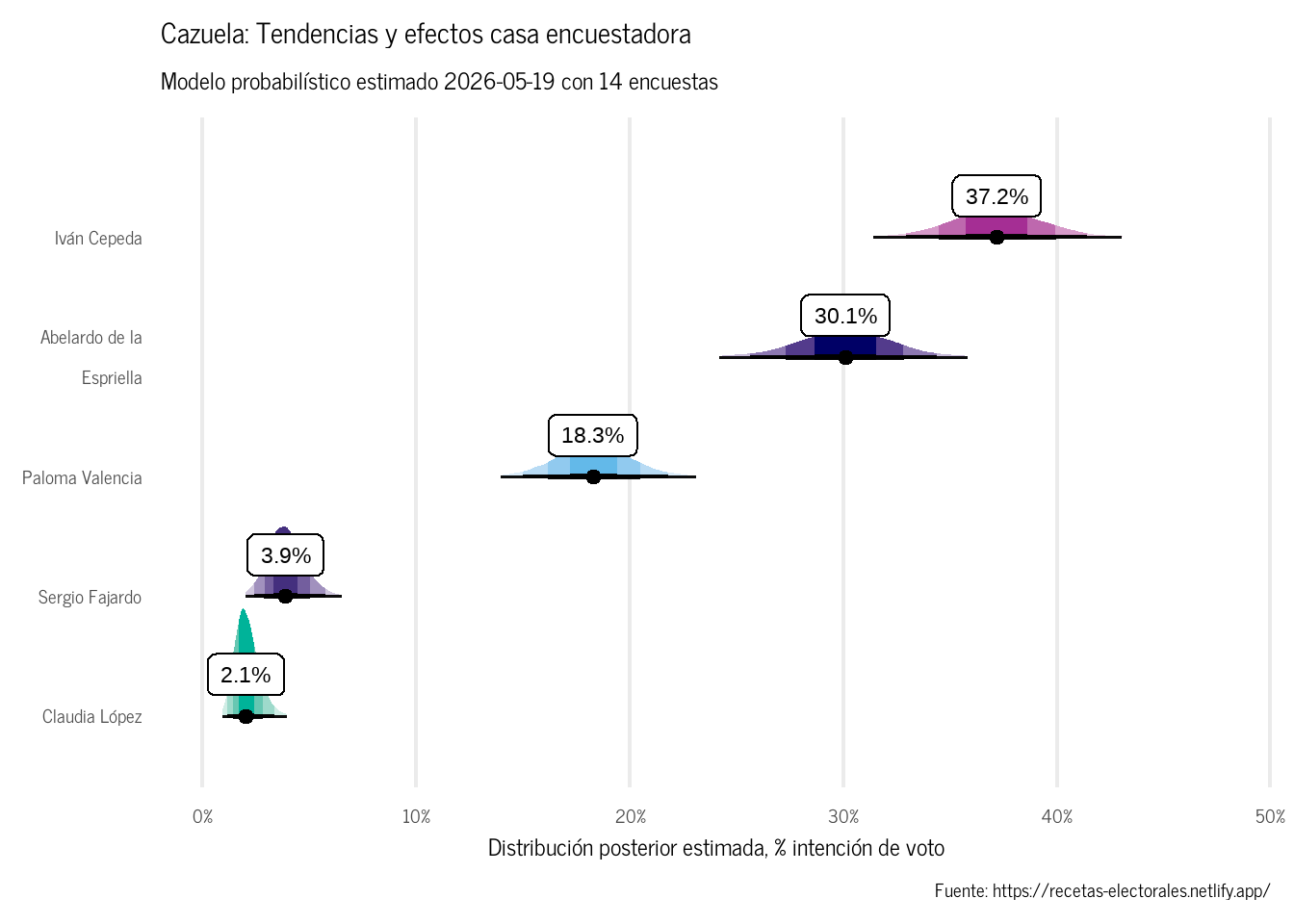
# Extraer p[j,k] para la encuesta más reciente ####J<-cazuela_data$JK<-cazuela_data$Kcand_names<-colnames(conteos_2026)# Usar las proporciones de la última encuesta (más reciente en el tiempo)cols_last<-paste0("p[", J, ",", 1:K, "]")cazuela_fit|>posterior::as_draws_df()|>tibble::as_tibble()|>dplyr::select(dplyr::all_of(cols_last))|>dplyr::rename_with(~paste0("p_", cand_names), .cols =dplyr::everything())|>tidyr::pivot_longer(cols =dplyr::everything(), names_to ="candidato", values_to ="prop")|>dplyr::mutate(candidato =stringr::str_sub(candidato, start =3L))|>dplyr::group_by(candidato)|>dplyr::mutate(candidato_m =mean(prop), .group_by ="drop")|># Nombresdplyr::left_join(candidatos_2026|>dplyr::mutate(candidato =paste0("cand_", cod)), by ="candidato")|># Quitar ruidodplyr::filter(!stringr::str_detect(candidato, "ruido"))|>ggplot2::ggplot(ggplot2::aes(x =prop, y =reorder(nombre, candidato_m)))+ggdist::stat_dist_slabinterval(ggplot2::aes( fill =color_cand, fill_ramp =ggplot2::after_stat(level)), .width =c(0.5, 0.8, 0.95, 0.99), interval_alpha =0.95, show.legend =c(fill =FALSE, fill_ramp =TRUE, size =FALSE))+ggdist::stat_pointinterval(ggplot2::aes(label =scales::percent(candidato_m, accuracy =0.1)), geom ="label", .width =0, vjust =-0.5, fill ="white", color ="black")+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_y_discrete(labels =scales::label_wrap(20))+ggplot2::scale_fill_identity(na.translate =FALSE)+ggdist::scale_fill_ramp_discrete( name ="Intervalo creíble", range =c(0.25, 1), breaks =c(0.5, 0.8, .95, 0.99), labels =c("50%", "80%", "95%", "99%"), na.translate =FALSE)+ggplot2::labs( title ="Cazuela: Tendencias y efectos casa encuestadora", subtitle =paste0("Modelo probabilístico estimado ", Sys.Date(), " con ", dplyr::n_distinct(encuestas_2026$encuesta_id)," encuestas"), caption ="Fuente: https://recetas-electorales.netlify.app/", x ="Distribución posterior estimada, % intención de voto", y =NULL)+ggplot2::theme_minimal(base_size =18)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.major.y =ggplot2::element_blank(), panel.grid.minor =ggplot2::element_blank(), legend.position ="none")
Figura 1: Cazuela: Dirichlet-Multinomial con covariables
Valencia o De la Espriella? Competencia probabilística
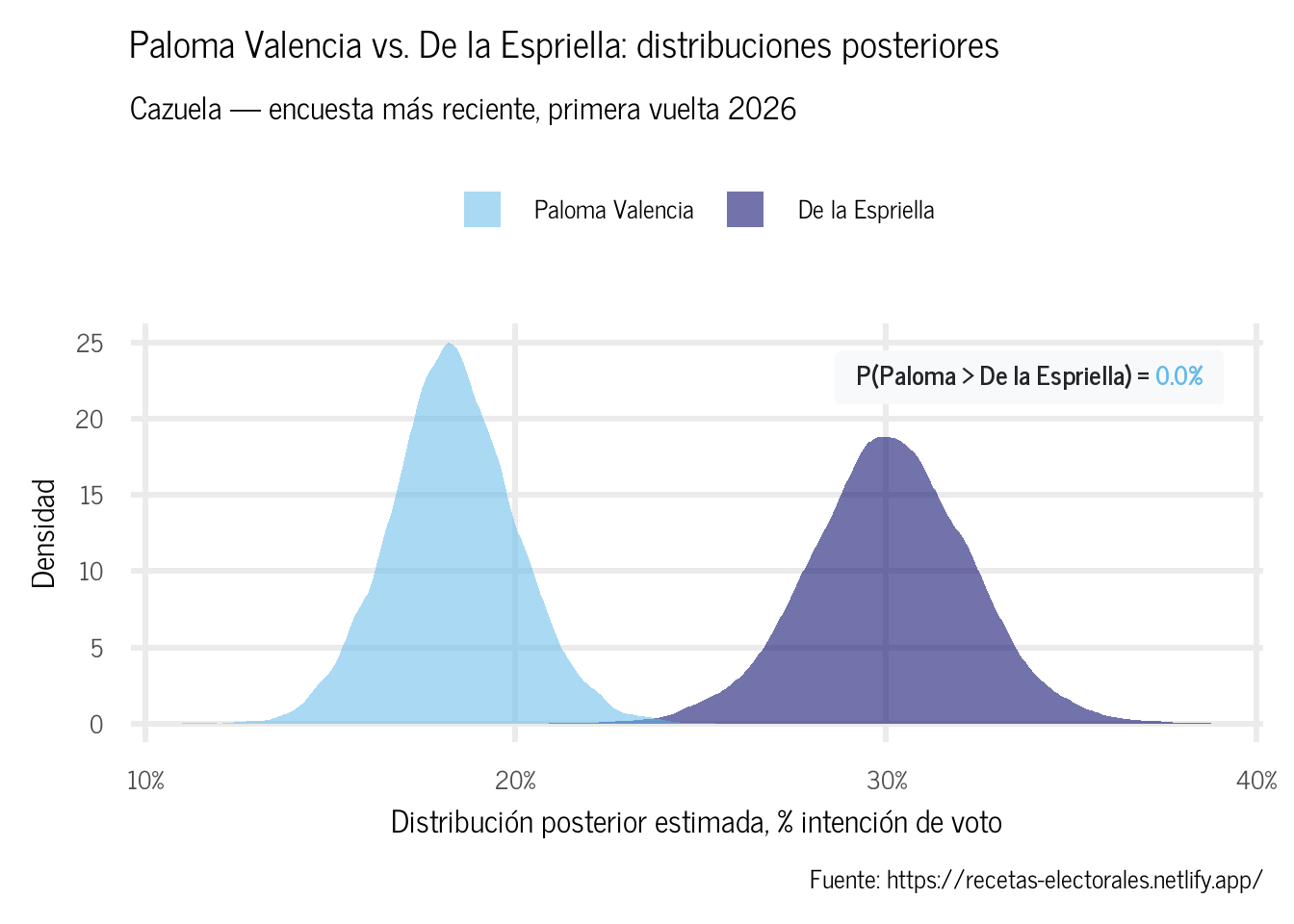
Una ventaja del enfoque bayesiano es que las comparaciones directas entre candidatos son triviales: basta con calcular la fracción de draws en los que la proporción de un candidato supera la del otro.
Según la Cazuela a 19 Mayo 2026, la probabilidad posterior de que Paloma Valencia obtenga más votos que De la Espriella en primera vuelta es 0.0%.
Ver código
library(ggtext)draws_comp|>tidyr::pivot_longer( cols =c(p_cand_pv, p_cand_adle), names_to ="candidato", values_to ="prop")|>dplyr::mutate( color_cand =dplyr::case_when(candidato=="p_cand_pv"~"#63B9E9",candidato=="p_cand_adle"~"#000066"))|>ggplot2::ggplot(ggplot2::aes(x =prop, fill =color_cand))+ggplot2::geom_density(alpha =0.55, color =NA)+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_fill_identity( guide ="legend", labels =c("#63B9E9"="Paloma Valencia", "#000066"="De la Espriella"), breaks =c("#63B9E9", "#000066"))+ggtext::geom_richtext( data =tibble::tibble(x =Inf, y =Inf),ggplot2::aes( x =x, y =y, label =sprintf("<b>P(Paloma > De la Espriella) = <span style='color:#63B9E9'>%.1f%%</span></b>",prob_pv_gt_adle*100)), inherit.aes =FALSE, hjust =1.1, vjust =1.5, size =7, family ="news-cycle", fill ="#F8F9FA", color ="#212529", label.color =NA, label.padding =ggplot2::unit(c(0.4, 0.6, 0.4, 0.6), "lines"))+ggplot2::labs( title ="Paloma Valencia vs. De la Espriella: distribuciones posteriores", subtitle ="Cazuela — encuesta más reciente, primera vuelta 2026", x ="Distribución posterior estimada, % intención de voto", y ="Densidad", fill =NULL, caption ="Fuente: https://recetas-electorales.netlify.app/")+ggplot2::theme_minimal(base_size =24)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), legend.position ="top")
Figura 2: Distribuciones posteriores de Paloma Valencia y De la Espriella (encuesta más reciente).
Tendencia temporal
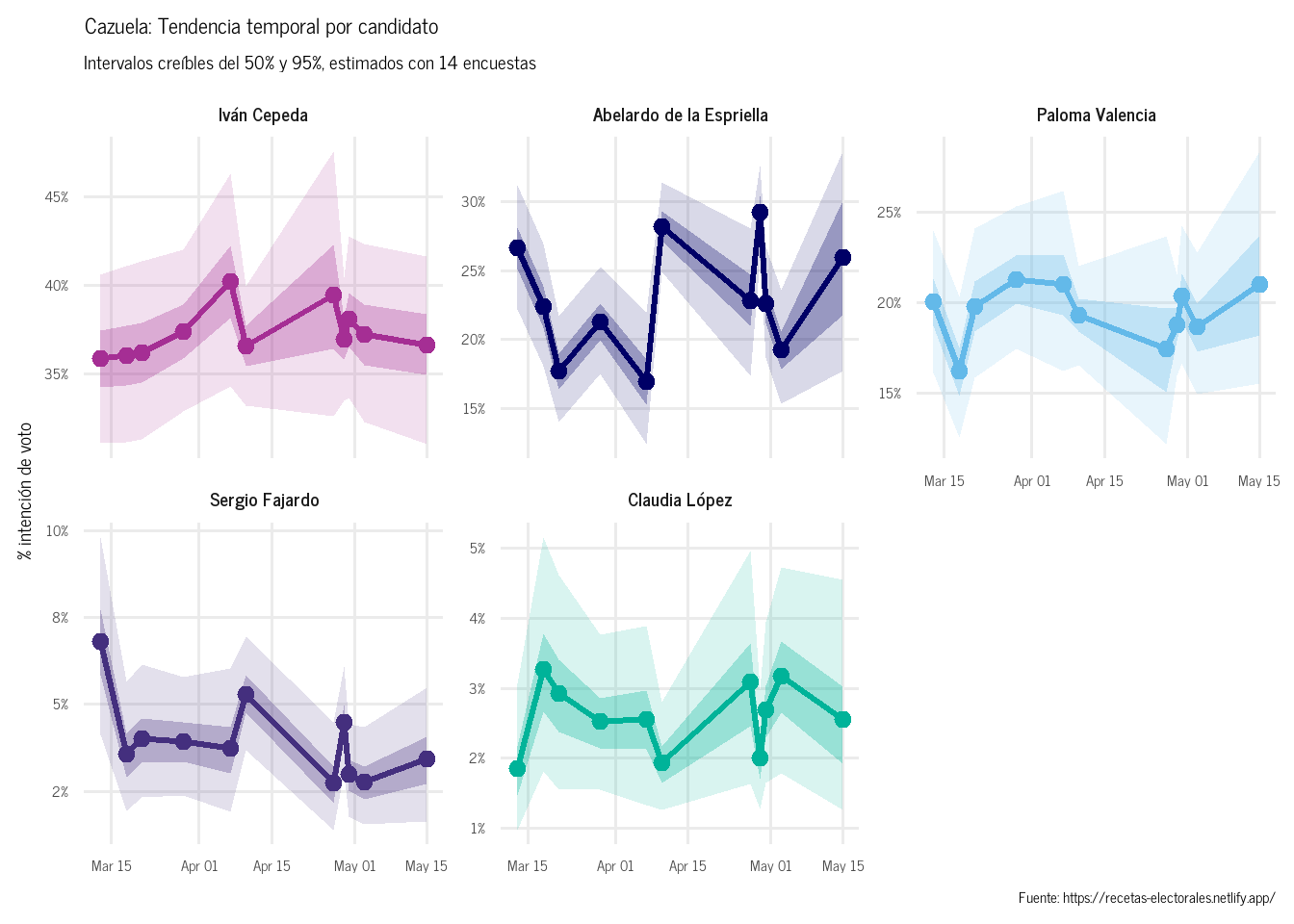
La gran ventaja de la Cazuela sobre el Ajiaco2 es que podemos visualizar cómo han cambiado las proporciones estimadas a lo largo del tiempo, corrigiendo por el efecto casa de cada encuestadora Figura 3.
Ver código
# Extraer p[j,k] para todas las encuestas ####draws_all<-cazuela_fit|>posterior::as_draws_df()|>tibble::as_tibble()# Construir data.frame largo con p[j,k] para cada draw y encuestap_draws<-purrr::map_dfr(1:J, function(j){# Seleccionar columnas exactas p[j,1], p[j,2], ..., p[j,K]cols_j<-paste0("p[", j, ",", 1:K, "]")draws_all|>dplyr::select(dplyr::all_of(cols_j))|>dplyr::rename_with(~cand_names, .cols =dplyr::everything())|>dplyr::mutate(.draw =dplyr::row_number(), .stan_idx =j)})|>dplyr::left_join(encuestas_meta|>dplyr::mutate(.stan_idx =dplyr::row_number()), by =".stan_idx")|>dplyr::select(-".stan_idx")|>tidyr::pivot_longer( cols =dplyr::all_of(cand_names), names_to ="candidato", values_to ="prop")|>dplyr::mutate(cod =stringr::str_sub(candidato, start =6L))|>dplyr::left_join(candidatos_2026, by =c("cod"))|>dplyr::filter(cod!="ruido")# Resumir por fecha y candidatop_summary<-p_draws|>dplyr::group_by(fecha, nombre, color_cand, cod)|>dplyr::summarise( media =mean(prop), q025 =quantile(prop, 0.025), q975 =quantile(prop, 0.975), q25 =quantile(prop, 0.25), q75 =quantile(prop, 0.75), .groups ="drop")# Orden global de candidatos por media posterior (usado en todas las gráficas)orden_candidatos<-p_summary|>dplyr::group_by(nombre)|>dplyr::summarise(media_global =mean(media), .groups ="drop")|>dplyr::arrange(dplyr::desc(media_global))|>dplyr::pull(nombre)p_summary|>dplyr::mutate(nombre =factor(nombre, levels =orden_candidatos))|>ggplot2::ggplot(ggplot2::aes(x =fecha, y =media, color =color_cand, fill =color_cand))+ggplot2::geom_ribbon(ggplot2::aes(ymin =q025, ymax =q975), alpha =0.15, color =NA)+ggplot2::geom_ribbon(ggplot2::aes(ymin =q25, ymax =q75), alpha =0.3, color =NA)+ggplot2::geom_line(linewidth =1.2)+ggplot2::geom_point(size =2.5)+ggplot2::scale_color_identity()+ggplot2::scale_fill_identity()+ggplot2::scale_y_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::facet_wrap(~nombre, scales ="free_y", ncol =3)+ggplot2::labs( title ="Cazuela: Tendencia temporal por candidato", subtitle =paste0("Intervalos creíbles del 50% y 95%, estimados con ", dplyr::n_distinct(encuestas_2026$encuesta_id), " encuestas"), caption ="Fuente: https://recetas-electorales.netlify.app/", x =NULL, y ="% intención de voto")+ggplot2::theme_minimal(base_size =14)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), strip.text =ggplot2::element_text(face ="bold", size =14), legend.position ="none")
Figura 3: Tendencia temporal estimada por la Cazuela
Efectos de casa
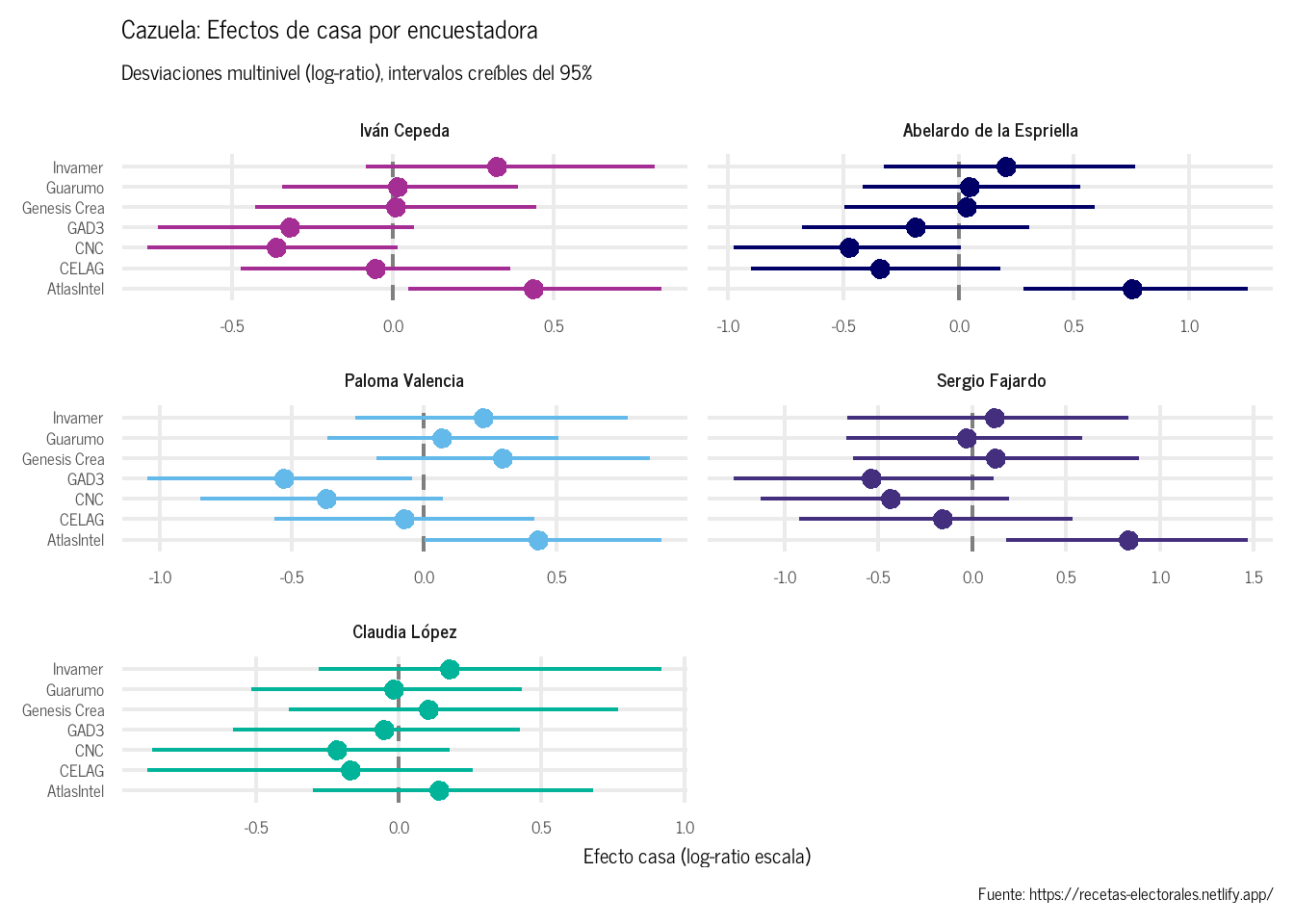
Cada encuestadora tiene un sesgo sistemático implícito. La Cazuela modela estos efectos de casa como un modelo multinivel de efectos aleatorios: cada vector \(\boldsymbol{\delta}_h \in \mathbb{R}^{K-1}\) se extrae de una distribución normal multivariada con matriz de covarianza estimada vía descomposición LKJ. Esto permite que el modelo aprenda si una encuestadora que sobreestima a un candidato tiende a subestimar a otro Figura 4.
Ver código
# Extraer delta[k, h] (nota: índices [k, h] en el modelo actualizado) ####K_minus_1<-K-1H<-cazuela_data$Hdelta_draws<-draws_all|>dplyr::select(dplyr::matches("^delta\\["))|>tidyr::pivot_longer(dplyr::everything(), names_to ="param", values_to ="value")|>dplyr::mutate( indices =stringr::str_extract(param, "\\[(.+)\\]", group =1), k =as.integer(stringr::str_extract(indices, "^\\d+")), h =as.integer(stringr::str_extract(indices, "\\d+$")), encuestadora =house_levels[h], candidato =cand_names[k], cod =stringr::str_sub(candidato, start =6L))|>dplyr::left_join(candidatos_2026, by =c("cod"))|>dplyr::filter(cod!="ruido")delta_summary<-delta_draws|>dplyr::group_by(encuestadora, nombre, color_cand, cod)|>dplyr::summarise( media =mean(value), q025 =quantile(value, 0.025), q975 =quantile(value, 0.975), .groups ="drop")delta_summary|>dplyr::mutate(nombre =factor(nombre, levels =orden_candidatos))|>ggplot2::ggplot(ggplot2::aes(x =media, y =encuestadora, color =color_cand))+ggplot2::geom_vline(xintercept =0, linetype ="dashed", color ="gray50")+ggplot2::geom_pointrange(ggplot2::aes(xmin =q025, xmax =q975), size =0.5)+ggplot2::scale_color_identity()+ggplot2::facet_wrap(~nombre, scales ="free_x", ncol =2)+ggplot2::labs( title ="Cazuela: Efectos de casa por encuestadora", subtitle ="Desviaciones multinivel (log-ratio), intervalos creíbles del 95%", caption ="Fuente: https://recetas-electorales.netlify.app/", x ="Efecto casa (log-ratio escala)", y =NULL)+ggplot2::theme_minimal(base_size =16)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), strip.text =ggplot2::element_text(face ="bold", size =14), legend.position ="none")
Figura 4: Efectos de casa estimados por la Cazuela
El partial pooling en acción
La característica más poderosa del modelo multinivel es el shrinkage: cada encuestadora es un punto en el espacio de estimaciones y el modelo las “jala” hacia el centro según cuánta evidencia tiene. La animación Figura 5 muestra cómo se mueve cada casa encuestadora entre tres escenarios:
Pooling completo: Todas colapsan al mismo punto, el promedio global.
Sin pooling: Cada encuestadora se estimada de forma independiente.
Partial pooling (Cazuela): El modelo jerárquico regula —las encuestadoras con pocas encuestas se encogen más hacia el centro que las que tienen varias muestras.
Figura 5: Pooling en la Cazuela
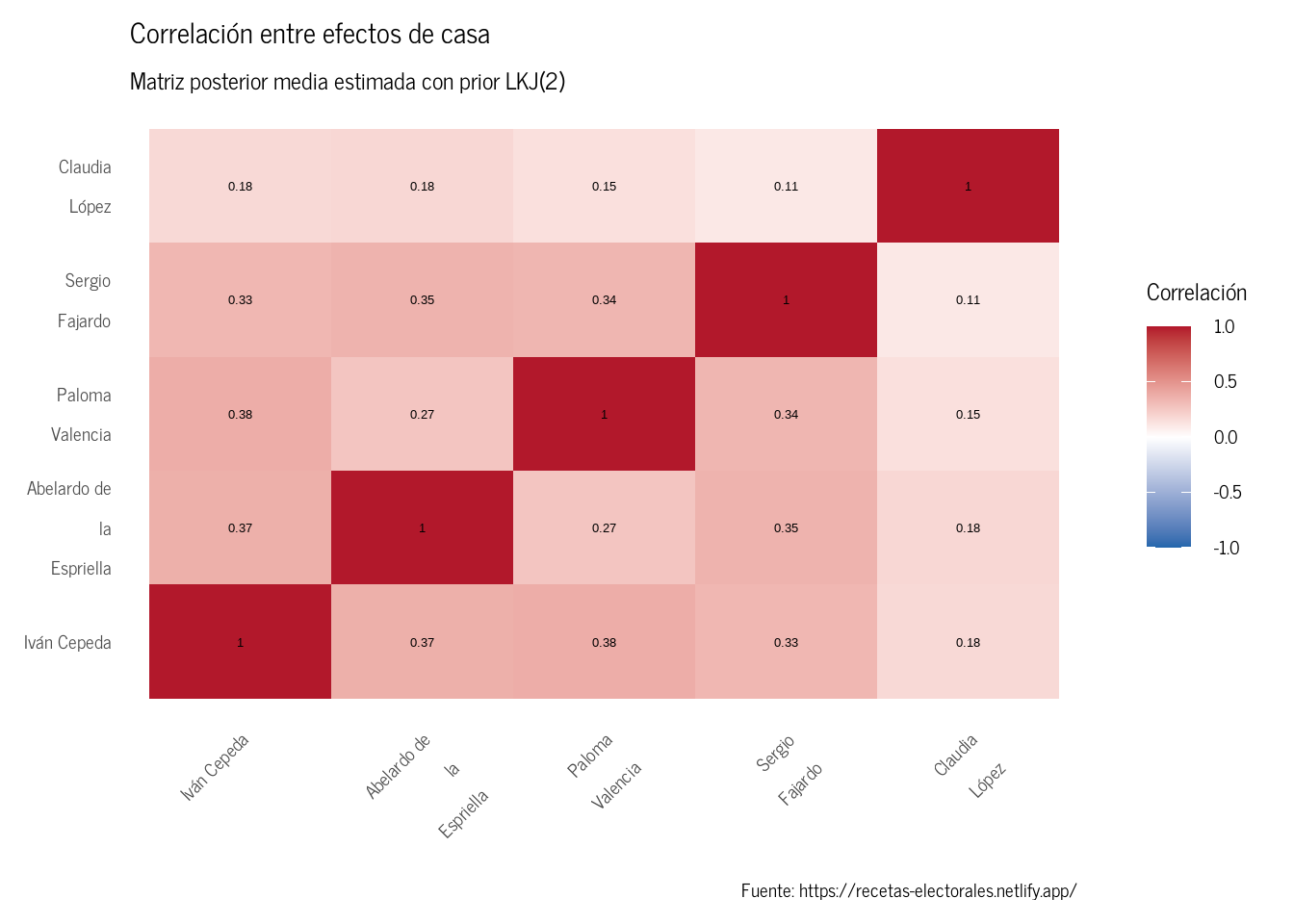
Correlación entre efectos de casa
El modelo estima explícitamente la matriz de correlación \(\Omega\) entre los efectos de casa de los candidatos usando un prior LKJ. Esto captura si las encuestadoras que sobreestiman a un candidato tienden a subestimar a otro Figura 6.
Ver código
# Extraer Omega[i,j] ####omega_draws<-draws_all|>dplyr::select(dplyr::matches("^Omega\\["))|>tidyr::pivot_longer(dplyr::everything(), names_to ="param", values_to ="value")|>dplyr::mutate( indices =stringr::str_extract(param, "\\[(.+)\\]", group =1), i =as.integer(stringr::str_extract(indices, "^\\d+")), j =as.integer(stringr::str_extract(indices, "\\d+$")))|>dplyr::group_by(i, j)|>dplyr::summarise(media =mean(value), .groups ="drop")|>dplyr::mutate( cand_i =cand_names[i], cand_j =cand_names[j], cod_i =stringr::str_sub(cand_i, start =6L), cod_j =stringr::str_sub(cand_j, start =6L))|>dplyr::left_join(candidatos_2026|>dplyr::select(cod, nombre), by =c("cod_i"="cod"))|>dplyr::rename(nombre_i =nombre)|>dplyr::left_join(candidatos_2026|>dplyr::select(cod, nombre), by =c("cod_j"="cod"))|>dplyr::rename(nombre_j =nombre)|>dplyr::filter(!is.na(nombre_i), !is.na(nombre_j))orden_corr<-orden_candidatos[orden_candidatos%in%unique(omega_draws$nombre_i)]omega_draws|>dplyr::mutate( nombre_i =factor(nombre_i, levels =orden_corr), nombre_j =factor(nombre_j, levels =orden_corr))|>ggplot2::ggplot(ggplot2::aes(x =nombre_i, y =nombre_j, fill =media))+ggplot2::geom_tile()+ggplot2::geom_text(ggplot2::aes(label =round(media, 2)), size =3.5)+ggplot2::scale_fill_gradient2(low ="#2166AC", mid ="white", high ="#B2182B", midpoint =0, limits =c(-1, 1), name ="Correlación")+ggplot2::scale_x_discrete(labels =scales::label_wrap(12))+ggplot2::scale_y_discrete(labels =scales::label_wrap(12))+ggplot2::labs( title ="Correlación entre efectos de casa", subtitle ="Matriz posterior media estimada con prior LKJ(2)", caption ="Fuente: https://recetas-electorales.netlify.app/", x =NULL, y =NULL)+ggplot2::theme_minimal(base_size =18)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), axis.text.x =ggplot2::element_text(angle =45, hjust =1), panel.grid =ggplot2::element_blank(), legend.position ="right")
Figura 6: Matriz de correlación posterior de efectos de casa
Diagnósticos
El muestreo MCMC:
Ver código
bayesplot::mcmc_trace(cazuela_fit$draws(), pars =ggplot2::vars(matches("beta0_raw")))
Receta Cazuela
La Cazuela extiende el Ajiaco2 al permitir que las proporciones de candidatos varíen por encuesta como función de covariables. En lugar de un solo vector \(\mathbf{p}\) pooled, cada encuesta \(j\) tiene su propio \(\mathbf{p}_j\) construido a partir de un predictor lineal con función de enlace softmax, como en un GLM multinomial.
La novedad clave es que los efectos de casa se modelan como efectos aleatorios multinivel con una estructura de covarianza completa. Los vectores \(\boldsymbol{\delta}_h\) se extraen de una distribución normal multivariada cuya matriz de covarianza se descompone en desviaciones estándar por candidato (\(\boldsymbol{\sigma}_\delta\)) y una matriz de correlación (\(\Omega\)) con prior LKJ. Se usa la parametrización no-centrada (\(\boldsymbol{\delta}_h = \mathrm{diag}(\boldsymbol{\sigma}_\delta) \cdot L_\Omega \cdot \mathbf{z}_h\)) para mejorar la eficiencia del muestreo MCMC:
Donde \(t_j\) es el tiempo centrado y escalado de la encuesta \(j\), \(h_j\) es el índice de la encuestadora, y \(L_\Omega\) es el factor Cholesky de la matriz de correlación \(\Omega\). El prior \(\mathrm{LKJ}(2)\) favorece correlaciones moderadas, lo que actúa como regularización contra matrices de correlación extremas.