Modelando las tendencias de todos los candidatos simultáneamente.
Autor/a
Afiliación
Recetas Electorales
Análisis independiente
Fecha de publicación
16 de mayo de 2026
Fecha de última modificación
19 de mayo de 2026
“A Gaussian process is a distribution over functions.” —Rasmussen & Williams
Introduciendo el Gaussiano
La Cazuela estimó tendencias con una regresión: para cada candidato, un intercepto y una pendiente en el tiempo. Eso captura dirección pero no forma: si un candidato primero cae y luego repunta, o si el cambio se acelera en las últimas semanas, la línea recta lo pierde.
El Gaussiano reemplaza esa línea recta con un Gaussian Process (GP): una distribución sobre funciones suaves que aprende la forma de la tendencia directamente de los datos. Curvatura, aceleración, rebotes —todo queda capturado.
Pero la innovación más importante es otra: los GPs de los candidatos están correlacionados. Si Claudia López gana terreno, ¿a quién le quita votos? ¿A Paloma Valencia? ¿A Fajardo? El modelo estima una matriz de correlación entre las trayectorias de todos los candidatos, revelando la dinámica competitiva de la carrera.
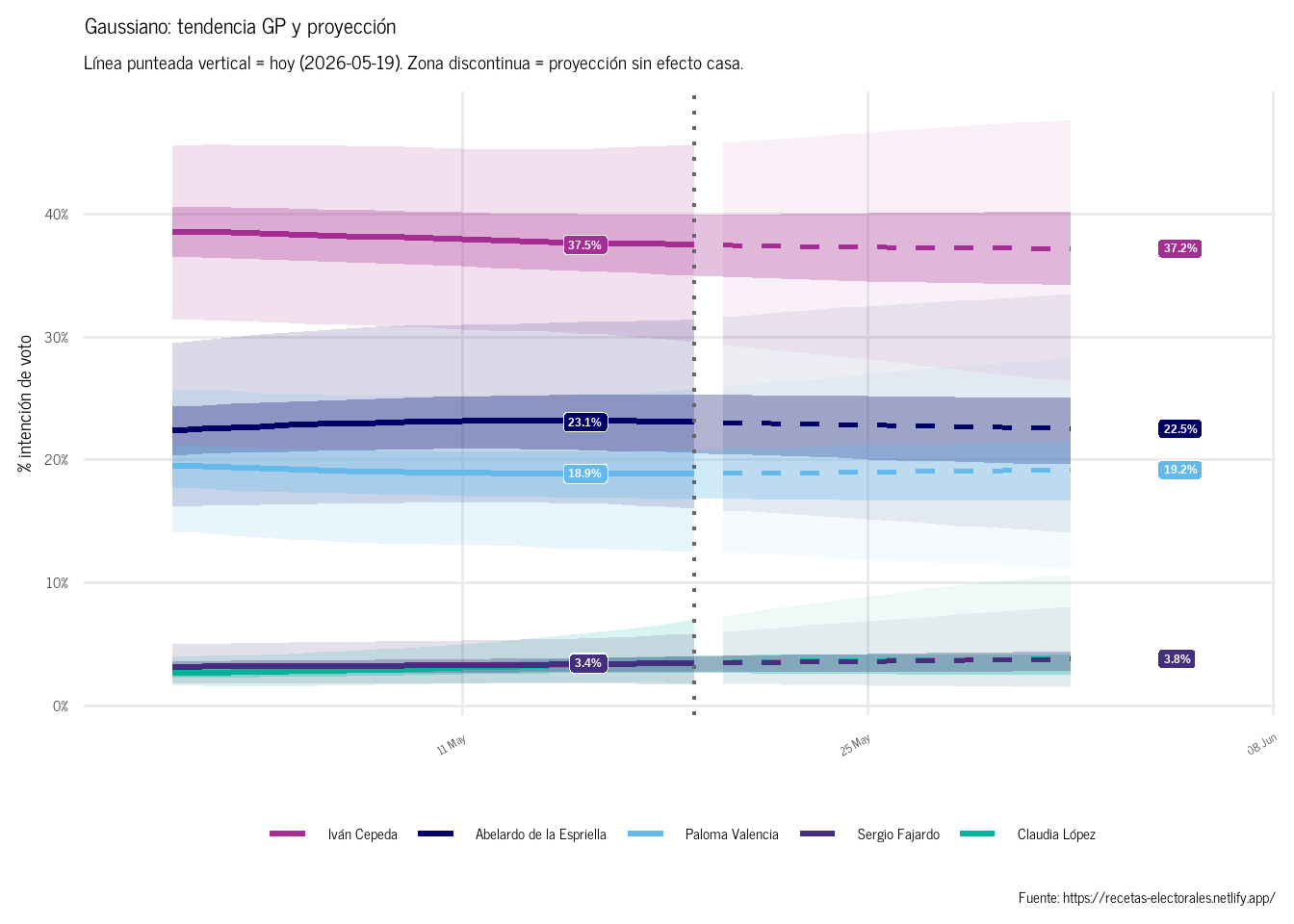
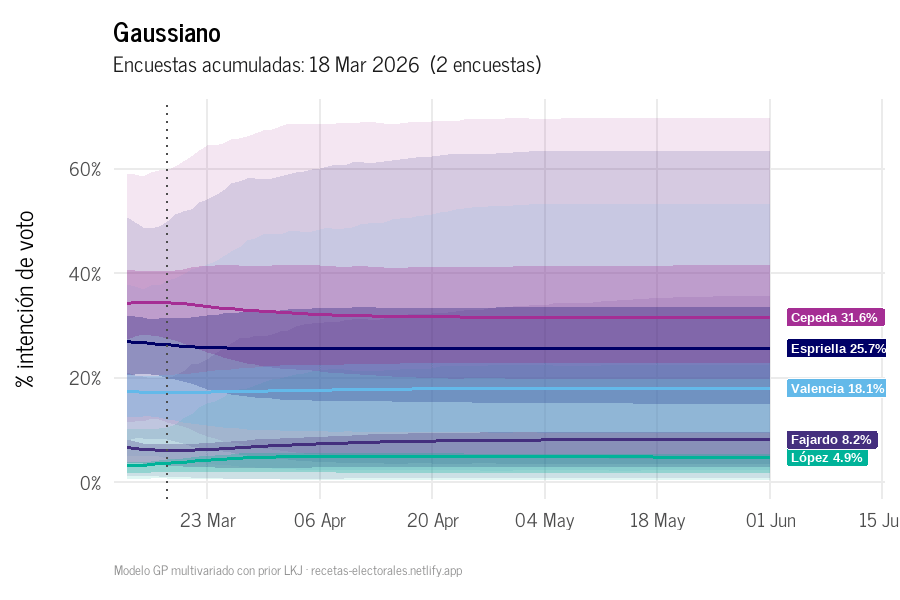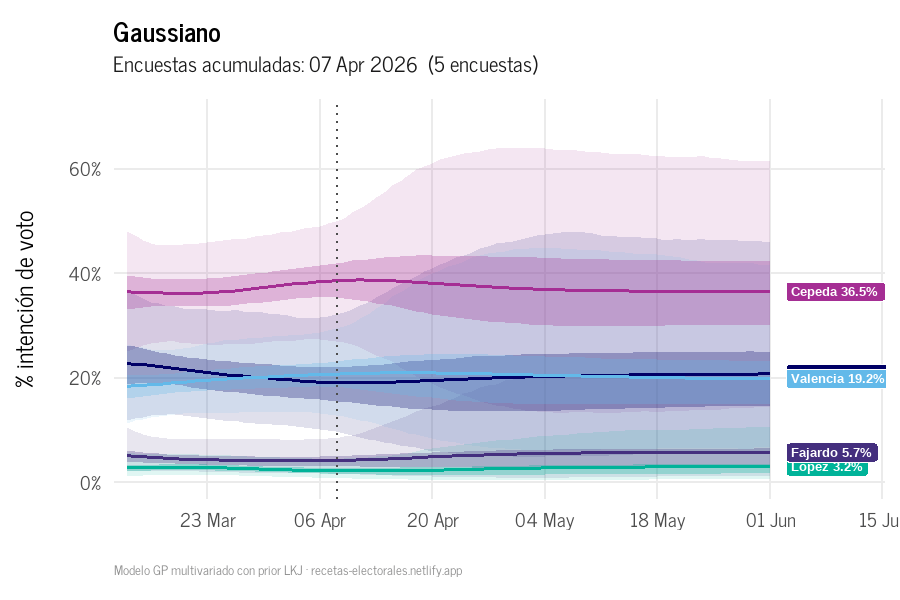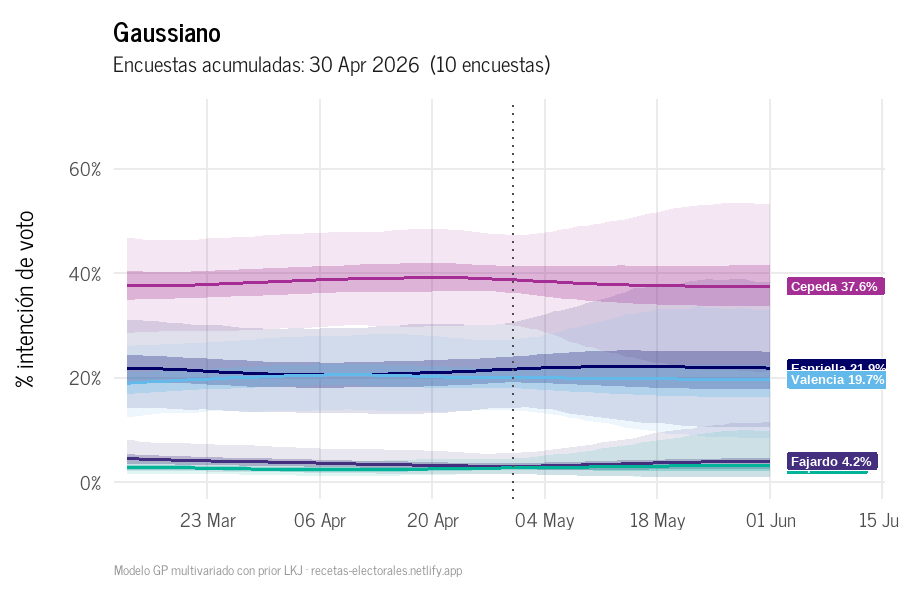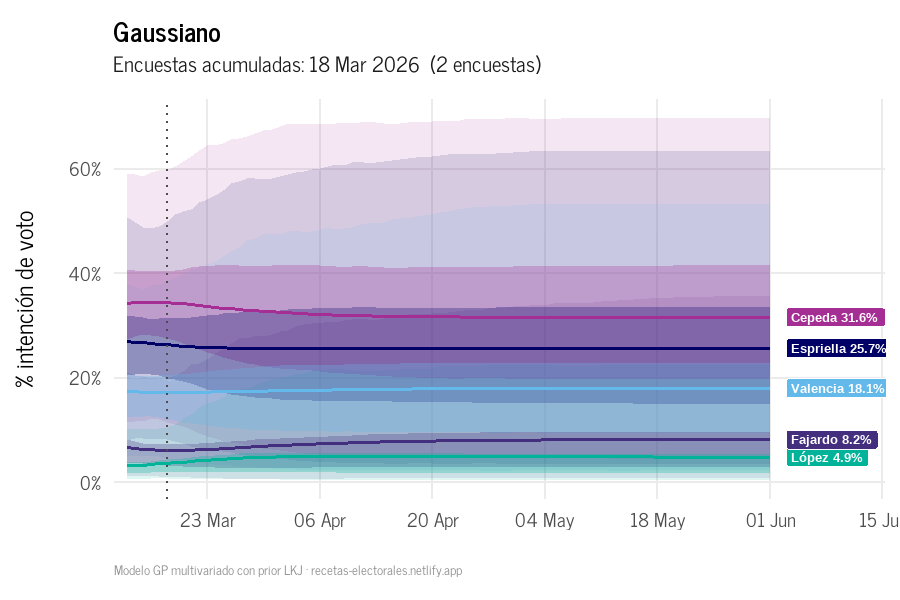
La ventaja del GP es visible en la siguiente gráfica Figura 1: las curvas ya no son líneas rectas. La región sombreada corresponde a la proyección hacia el futuro (sin efecto casa), donde la incertidumbre crece a medida que nos alejamos de los datos observados —comportamiento propio de un GP bien calibrado.
Ver código
fecha_hoy<-Sys.Date()p_pred_summary<-purrr::map_dfr(seq_len(J_pred), function(j2){cols_j<-paste0("p_pred[", j2, ",", seq_len(K), "]")draws_all|>dplyr::select(dplyr::all_of(cols_j))|>purrr::set_names(cand_names)|>tidyr::pivot_longer(dplyr::everything(), names_to ="candidato", values_to ="prop")|>dplyr::group_by(candidato)|>dplyr::summarise( media =mean(prop), q025 =quantile(prop, 0.025), q975 =quantile(prop, 0.975), q25 =quantile(prop, 0.25), q75 =quantile(prop, 0.75), .groups ="drop")|>dplyr::mutate(fecha =fecha_pred_seq[[j2]])})|>dplyr::mutate(cod =stringr::str_sub(candidato, start =6L))|>dplyr::left_join(candidatos_2026, by ="cod")|>dplyr::filter(cod!="ruido")orden_candidatos<-p_pred_summary|>dplyr::group_by(nombre)|>dplyr::summarise(media_global =mean(media), .groups ="drop")|>dplyr::arrange(dplyr::desc(media_global))|>dplyr::pull(nombre)fecha_inicio<-lubridate::ymd("2026-05-01")datos_plot<-p_pred_summary|>dplyr::filter(fecha>=fecha_inicio)|>dplyr::mutate( nombre =factor(nombre, levels =orden_candidatos), es_futuro =fecha>fecha_hoy)colores_leyenda<-datos_plot|>dplyr::distinct(nombre, color_cand)|>dplyr::arrange(match(nombre, orden_candidatos))etiquetas_hoy<-datos_plot|>dplyr::filter(!es_futuro)|>dplyr::group_by(nombre, color_cand)|>dplyr::filter(fecha==max(fecha))|>dplyr::ungroup()etiquetas_pred<-datos_plot|>dplyr::group_by(nombre, color_cand)|>dplyr::filter(fecha==max(fecha))|>dplyr::ungroup()datos_plot|>ggplot2::ggplot(ggplot2::aes(x =fecha, color =color_cand, fill =color_cand))+ggplot2::geom_ribbon(ggplot2::aes(ymin =q025, ymax =q975, alpha =es_futuro), color =NA)+ggplot2::geom_ribbon(ggplot2::aes(ymin =q25, ymax =q75), alpha =0.30, color =NA)+ggplot2::geom_line( data =~dplyr::filter(.x, !es_futuro),ggplot2::aes(y =media), linewidth =1.1)+ggplot2::geom_line( data =~dplyr::filter(.x, es_futuro),ggplot2::aes(y =media), linewidth =1.0, linetype ="dashed")+ggplot2::geom_vline( xintercept =as.numeric(fecha_hoy), linetype ="dotted", color ="gray40", linewidth =0.8)+ggplot2::geom_label( data =etiquetas_hoy,ggplot2::aes(y =media, label =scales::percent(media, accuracy =0.1), fill =color_cand), nudge_x =-3, hjust =1, color ="white", fontface ="bold", size =3.2, label.padding =ggplot2::unit(0.2, "lines"), show.legend =FALSE)+ggplot2::geom_label( data =etiquetas_pred,ggplot2::aes(y =media, label =scales::percent(media, accuracy =0.1), fill =color_cand), nudge_x =3, hjust =0, color ="white", fontface ="bold", size =3.2, label.padding =ggplot2::unit(0.2, "lines"), show.legend =FALSE)+ggplot2::scale_color_identity( guide ="legend", name =NULL, breaks =colores_leyenda$color_cand, labels =as.character(colores_leyenda$nombre))+ggplot2::scale_fill_identity()+ggplot2::scale_alpha_manual( values =c(`FALSE` =0.15, `TRUE` =0.07), guide ="none")+ggplot2::scale_y_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_x_date( date_labels ="%d %b", date_breaks ="2 weeks", expand =ggplot2::expansion(mult =c(0.09, 0.12)))+ggplot2::labs( title ="Gaussiano: tendencia GP y proyección", subtitle =paste0("Línea punteada vertical = hoy (", fecha_hoy,"). Zona discontinua = proyección sin efecto casa."), caption ="Fuente: https://recetas-electorales.netlify.app/", x =NULL, y ="% intención de voto")+ggplot2::theme_minimal(base_size =14)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), strip.text =ggplot2::element_text(face ="bold", size =13), axis.text.x =ggplot2::element_text(angle =30, hjust =1, size =9), legend.position ="bottom")
Figura 1: Tendencia GP por candidato: pasado y proyección a futuro
Evolución acumulada
La animación muestra cómo el GP actualiza las trayectorias a medida que se incorporan nuevas encuestas, con la proyección al 1° de junio.
Gaussiano: evolución acumulada de trayectorias GP
Valencia vs. De la Espriella: Proyecciones
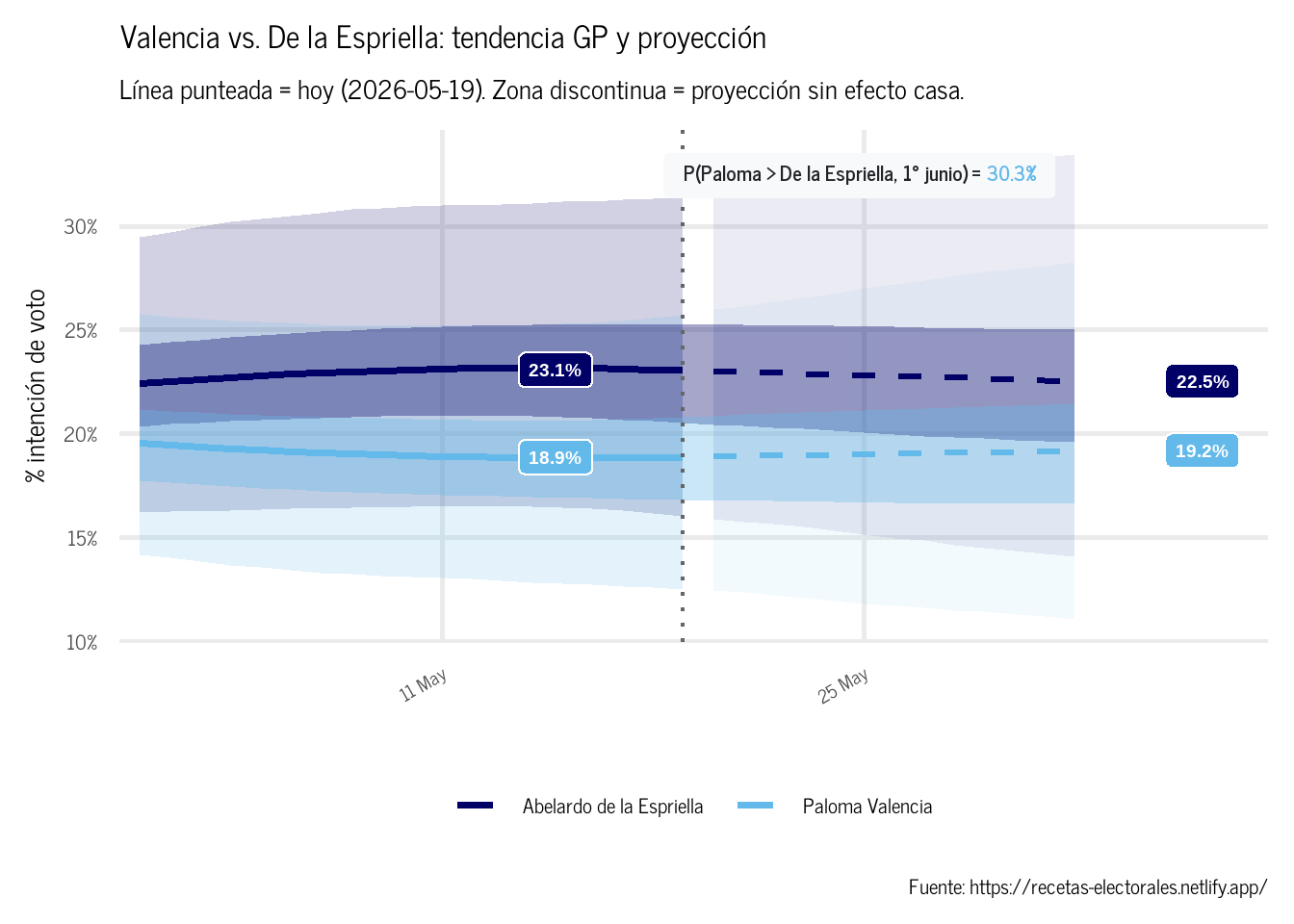
Paloma Valencia y Abelardo de la Espriella compiten por el mismo electorado de derecha. El GP permite ver si sus trayectorias se cruzan —o si una de las dos consolida la ventaja de cara al 1° de junio.
Ver código
library(ggtext)k_pv<-which(cand_names=="cand_pv")k_adle<-which(cand_names=="cand_adle")prob_pv_gt_adle_gp<-mean(draws_all[[paste0("p_pred[", J_pred, ",", k_pv, "]")]]>draws_all[[paste0("p_pred[", J_pred, ",", k_adle, "]")]])duo_plot<-p_pred_summary|>dplyr::filter(cod%in%c("pv", "adle"),fecha>=lubridate::ymd("2026-05-01"))|>dplyr::mutate(es_futuro =fecha>fecha_hoy)duo_etiquetas_hoy<-duo_plot|>dplyr::filter(!es_futuro)|>dplyr::group_by(nombre, color_cand)|>dplyr::filter(fecha==max(fecha))|>dplyr::ungroup()duo_etiquetas_pred<-duo_plot|>dplyr::group_by(nombre, color_cand)|>dplyr::filter(fecha==max(fecha))|>dplyr::ungroup()duo_colores<-duo_plot|>dplyr::distinct(nombre, color_cand)duo_plot|>ggplot2::ggplot(ggplot2::aes(x =fecha, color =color_cand, fill =color_cand))+ggplot2::geom_ribbon(ggplot2::aes(ymin =q025, ymax =q975, alpha =es_futuro), color =NA)+ggplot2::geom_ribbon(ggplot2::aes(ymin =q25, ymax =q75), alpha =0.35, color =NA)+ggplot2::geom_line( data =~dplyr::filter(.x, !es_futuro),ggplot2::aes(y =media), linewidth =1.3)+ggplot2::geom_line( data =~dplyr::filter(.x, es_futuro),ggplot2::aes(y =media), linewidth =1.2, linetype ="dashed")+ggplot2::geom_vline( xintercept =as.numeric(fecha_hoy), linetype ="dotted", color ="gray40", linewidth =0.8)+ggplot2::geom_label( data =duo_etiquetas_hoy,ggplot2::aes(y =media, label =scales::percent(media, accuracy =0.1), fill =color_cand), nudge_x =-3, hjust =1, color ="white", fontface ="bold", size =5, show.legend =FALSE)+ggplot2::geom_label( data =duo_etiquetas_pred,ggplot2::aes(y =media, label =scales::percent(media, accuracy =0.1), fill =color_cand), nudge_x =3, hjust =0, color ="white", fontface ="bold", size =5, show.legend =FALSE)+ggtext::geom_richtext( data =tibble::tibble(x =max(duo_plot$fecha), y =Inf),ggplot2::aes( x =x, y =y, label =sprintf("<b>P(Paloma > De la Espriella, 1° junio) = <span style='color:#63B9E9'>%.1f%%</span></b>",prob_pv_gt_adle_gp*100)), inherit.aes =FALSE, hjust =1.05, vjust =1.5, size =5.5, family ="news-cycle", fill ="#F8F9FA", color ="#212529", label.color =NA, label.padding =ggplot2::unit(c(0.35, 0.55, 0.35, 0.55), "lines"))+ggplot2::scale_color_identity( guide ="legend", name =NULL, breaks =duo_colores$color_cand, labels =duo_colores$nombre)+ggplot2::scale_fill_identity()+ggplot2::scale_alpha_manual(values =c(`FALSE` =0.18, `TRUE` =0.08), guide ="none")+ggplot2::scale_y_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_x_date( date_labels ="%d %b", date_breaks ="2 weeks", expand =ggplot2::expansion(mult =c(0.02, 0.10)))+ggplot2::labs( title ="Valencia vs. De la Espriella: tendencia GP y proyección", subtitle =paste0("Línea punteada = hoy (", fecha_hoy,"). Zona discontinua = proyección sin efecto casa."), caption ="Fuente: https://recetas-electorales.netlify.app/", x =NULL, y ="% intención de voto")+ggplot2::theme_minimal(base_size =20)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), axis.text.x =ggplot2::element_text(angle =30, hjust =1, size =14), legend.position ="bottom")
Figura 2: Trayectoria GP y proyección: Paloma Valencia y Abelardo de la Espriella
Ver código
library(ggtext)draws_duo<-tibble::tibble( p_pv =draws_all[[paste0("p_pred[", J_pred, ",", k_pv, "]")]], p_adle =draws_all[[paste0("p_pred[", J_pred, ",", k_adle, "]")]])|>tidyr::pivot_longer( cols =c(p_pv, p_adle), names_to ="candidato", values_to ="prop")|>dplyr::mutate( color_cand =dplyr::case_when(candidato=="p_pv"~"#63B9E9",candidato=="p_adle"~"#000066"))draws_duo|>ggplot2::ggplot(ggplot2::aes(x =prop, fill =color_cand))+ggplot2::geom_density(alpha =0.55, color =NA)+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_fill_identity( guide ="legend", labels =c("#63B9E9"="Paloma Valencia", "#000066"="De la Espriella"), breaks =c("#63B9E9", "#000066"))+ggtext::geom_richtext( data =tibble::tibble(x =Inf, y =Inf),ggplot2::aes( x =x, y =y, label =sprintf("<b>P(Paloma > De la Espriella, 1° junio) = <span style='color:#63B9E9'>%.1f%%</span></b>",prob_pv_gt_adle_gp*100)), inherit.aes =FALSE, hjust =1.1, vjust =1.5, size =7, family ="news-cycle", fill ="#F8F9FA", color ="#212529", label.color =NA, label.padding =ggplot2::unit(c(0.4, 0.6, 0.4, 0.6), "lines"))+ggplot2::labs( title ="Paloma Valencia vs. De la Espriella: distribuciones posteriores al 1° de junio", subtitle ="Modelo Gaussiano — proyección primera vuelta 2026", x ="% intención de voto proyectado", y ="Densidad", fill =NULL, caption ="Fuente: https://recetas-electorales.netlify.app/")+ggplot2::theme_minimal(base_size =24)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), legend.position ="top")
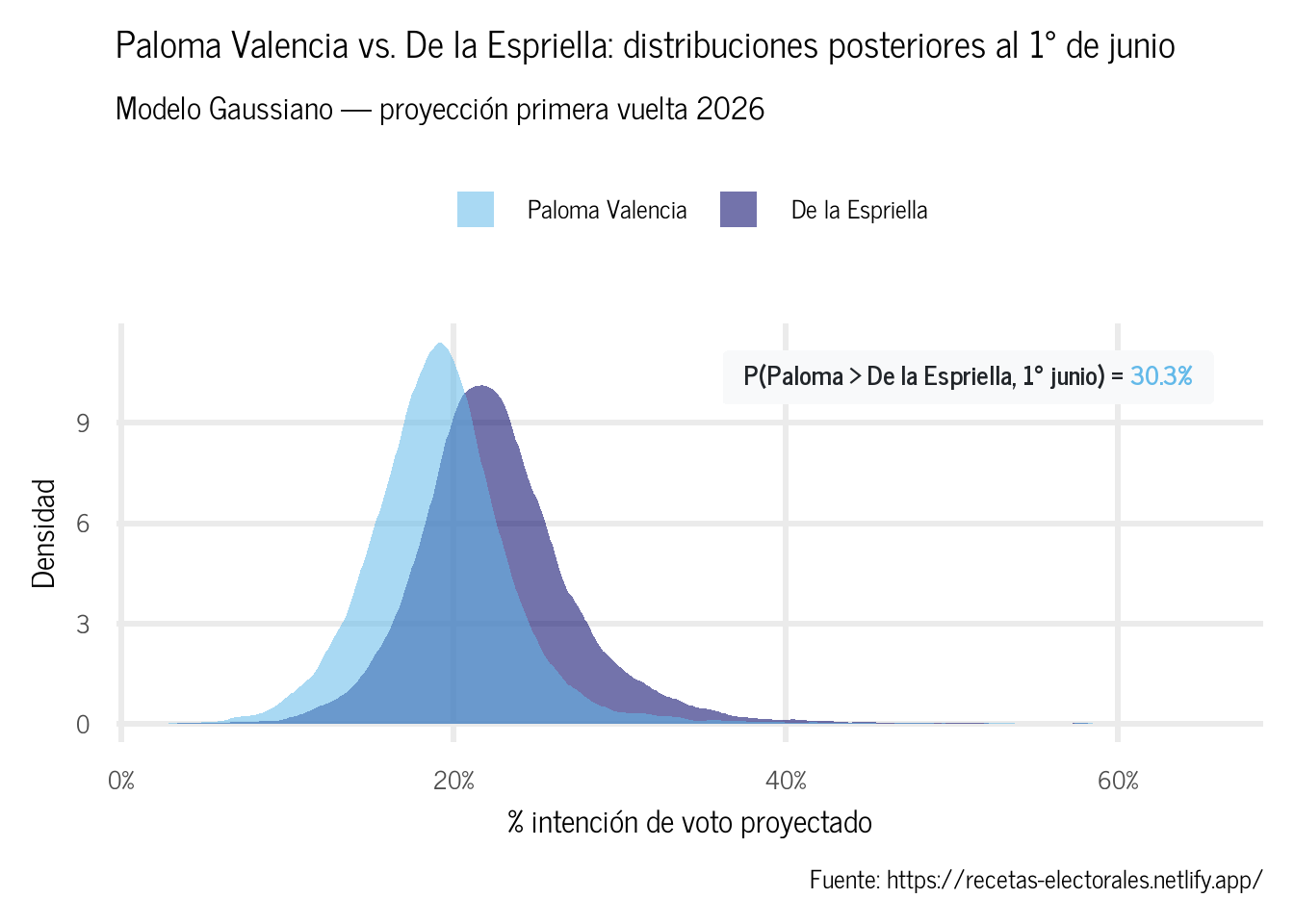
Figura 3: Distribuciones posteriores de Paloma Valencia y De la Espriella al 1° de junio (Gaussiano)
Diagnósticos
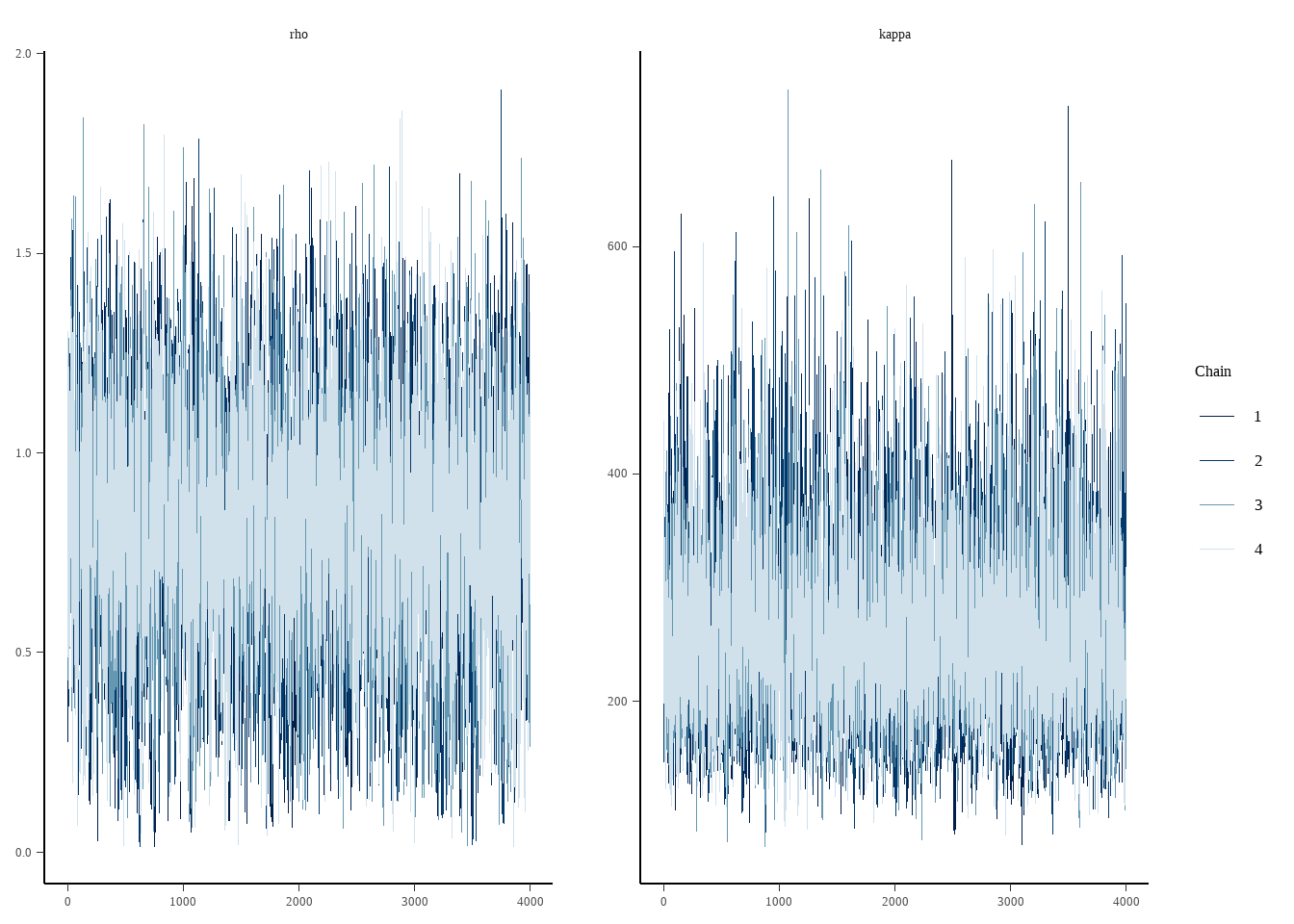
Escala de longitud del GP (\(\rho\)) y parámetros de concentración:
El GP multivariado se implementa via el Linear Model of Coregionalization (LMC): la covarianza total es el producto de Kronecker entre la covarianza temporal (\(K_t\)) y la covarianza entre candidatos (\(\mathrm{diag}(\boldsymbol{\alpha})\,\Omega_{GP}\,\mathrm{diag}(\boldsymbol{\alpha})\)). Esto hace al modelo separable, permitiendo la parametrización no-centrada eficiente y el cómputo de la media posterior en la grilla de predicción vía \(\hat{f}_{\text{pred}} = K(t_*, t)\,K_t^{-1}\,f_{\text{obs}}\).
library(brms)# Un fila por encuesta, con conteos y tiempo escalado como columnasdatos_brm<-dplyr::bind_cols(encuestas_meta,tibble::as_tibble(conteos_2026),tibble::tibble(time_scaled =time_scaled))# GP suavizante por categoría + efecto de encuestadora# brms genera un GP separado (lscale, sdgp propios) para cada log-ratioform_brm<-brms::bf(cbind(cand_ic, cand_adle, cand_pv, cand_sf, cand_cl, cand_ruido)|trials(muestra)~gp(time_scaled, scale =FALSE)+(1|encuestadora))# Priors aproximando los del modelo Stanpriors_brm<-c(brms::prior(normal(0, 2), class =Intercept),brms::prior(normal(0.5, 0.3), class =lscale, lb =0),brms::prior(normal(0, 1), class =sdgp, lb =0),brms::prior(normal(0, 1), class =sd, lb =0))gp_brms_fit<-brms::brm(form_brm, data =datos_brm, family =brms::multinomial(refcat ="cand_ruido"), prior =priors_brm, seed =42, chains =4, cores =4, iter =5000, warmup =1000, control =list(adapt_delta =0.95, max_treedepth =12), backend ="cmdstanr")# Tendencia pura (sin efecto casa) en la grilla de predicciónnewdata_brm<-tibble::tibble( time_scaled =time_pred_scaled, encuestadora =factor(NA, levels =levels(encuestas_meta$encuestadora)), muestra =1000L)pred_brm<-brms::posterior_epred(gp_brms_fit, newdata =newdata_brm, allow_new_levels =TRUE, re_formula =NA# marginaliza sobre el efecto casa)