Un mejor modelo que le saca más provecho a la poca información disponible
Autor/a
Afiliación
Recetas Electorales
Análisis independiente
Fecha de publicación
25 de abril de 2018
Fecha de última modificación
10 de febrero de 2022
“Linear regression is the geocentric model of applied statistics.” –Richard McElreath
📅 Publicado 25 Abril 2018, Actualizado 10 Febrero 2022
El Plato Simple logra mucho con muy poco. Pero desaprovecha la poca información que hay. El Plato Mixto le saca más jugo a lo que hay. Requiere más tiempo en la cocina y usa nuevos ingredientes, pero el resultado lo justifica.
El truco del plato mixto es explotar relaciones entre las características de las encuestas. Por ejemplo, que las encuestas más pequeñas son, a la vez, las que se hacen por teléfono y no presencialmente. En términos estadísticos, esta receta es un modelo mixto que extiende los efectos aleatorios por encuestadora que tenía la primera receta (\(\alpha_{encuestadora[i]}\)) a los coeficientes de las otras variables explicativas (\(\beta_{encuestadora[i]}\)).
¿Qué se logra con eso? Un mejor plato. ¿Por qué? No tengo la menor idea sobre cómo decir eso en español, o en metáfora culinaria, pero la idea es que cuando hay clusters que no tienen un órden determinado en los datos, como en este caso son las encuestadoras, se puede modelar simultáneamente lo que está dentro de esos clusters y usar esas inferencias para agrupar (pool) información entre los parámetros.
Siéntase libre de leer por encima, o ignorar, lo que le parezca demasiado técnico. No se pierde de mucho. De cualquier forma, la apuesta de este ejercicio no cambia: la transparencia es algo que se hace, no algo que se dice. Aquí no hay salsa secreta.
Platos servidos
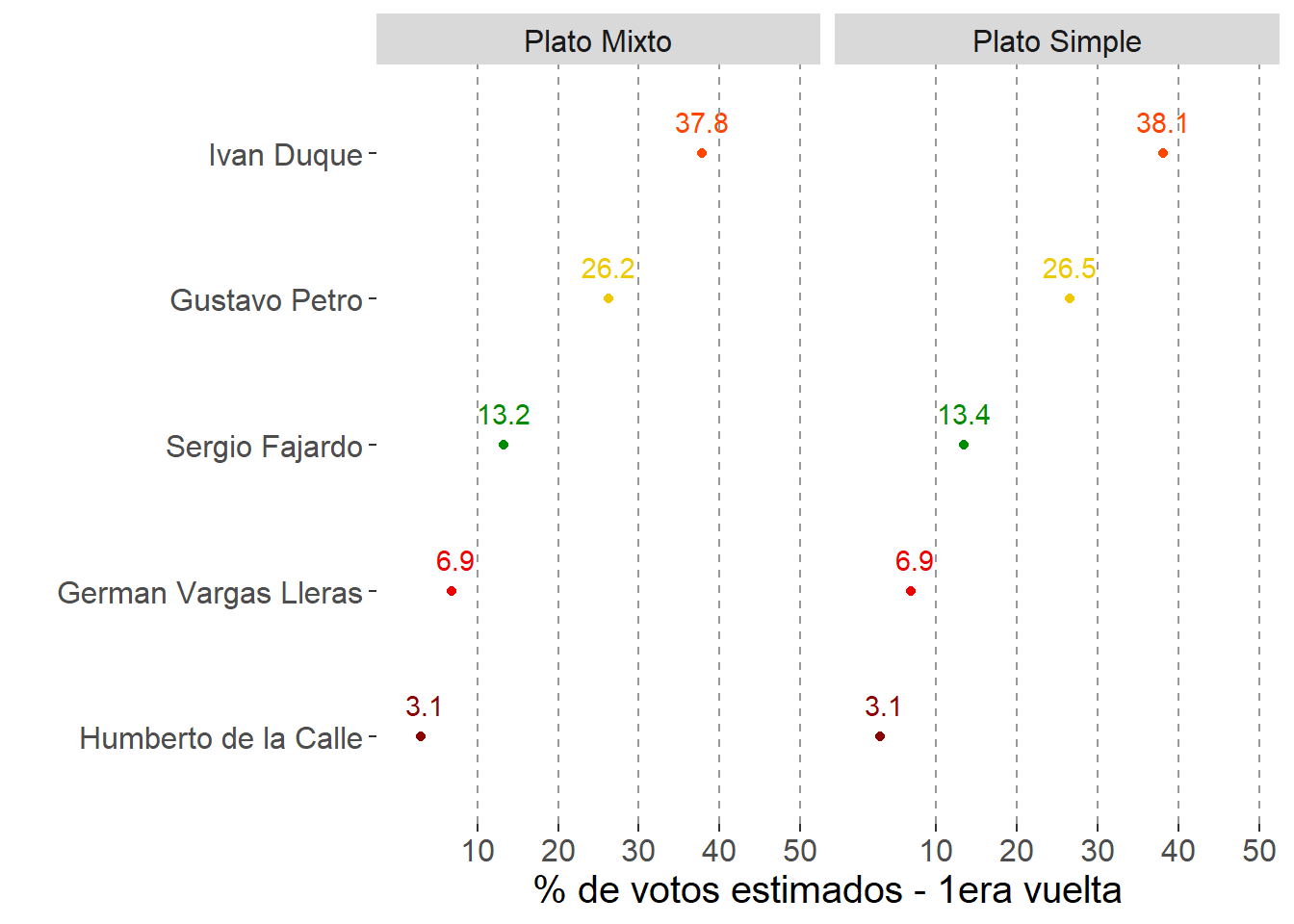
Primero veamos cómo se comparan los resultados de Plato Mixto con los del Plato Simple. En ambos casos el resultado es el promedio de la estimación de los parámetros y el HPDI de 90% de cada uno. Los valores cambian con cada estimación. Eso refleja la incorporación de nueva información y la forma como la receta los procesa.
Ver código
library(tidyverse)library(here)# Plato servido ####readr::read_csv(here("elecciones","2018-colombia","2018-04-25-mixto-2018","simple-2018","simple_2018_resultados.csv"))%>%dplyr::group_by(nombre)%>%dplyr::summarise(m_all =median(value), p10 =quantile(value,0.1), p90 =quantile(value,0.9))%>%dplyr::mutate(plato="Plato Simple")%>%dplyr::select(plato,candidato=nombre,int_voto=m_all,int_voto_min=p10,int_voto_max=p90)%>%dplyr::mutate(candidato=factor(candidato,levels=c("Humberto de la Calle","German Vargas Lleras","Sergio Fajardo","Gustavo Petro","Ivan Duque")))%>%dplyr::bind_rows(readr::read_csv(here("elecciones","2018-colombia","2018-04-25-mixto-2018","mixto-2018","mixto_2018_resultados.csv"))%>%dplyr::group_by(nombre)%>%dplyr::summarise(m_all =median(value), p10 =quantile(value,0.1), p90 =quantile(value,0.9))%>%dplyr::mutate(plato="Plato Mixto")%>%dplyr::select(plato,candidato=nombre,int_voto=m_all,int_voto_min=p10,int_voto_max=p90)%>%dplyr::mutate(candidato=factor(candidato,levels=c("Humberto de la Calle","German Vargas Lleras","Sergio Fajardo","Gustavo Petro","Ivan Duque"))))%>%dplyr::mutate(plato=factor(plato))%>%ggplot2::ggplot(ggplot2::aes(x=candidato, color=candidato))+#platoggplot2::geom_point(ggplot2::aes(y=int_voto))+ggplot2::geom_text(ggplot2::aes(y=int_voto,label=format(int_voto,digits=2)),vjust=-1)+ggplot2::geom_hline(yintercept=c(10,20,30,40,50),linetype="dashed",color="grey60")+#referencias#ggplot2::geom_point(ggplot2::aes(y=m_03.2018), shape=9,size=5)+#ggplot2::geom_text(ggplot2::aes(y=m_03.2018, label="11.03.2018",angle=90),size=2,hjust=1.4)+ggplot2::coord_flip()+#facetggplot2::facet_wrap(~plato)+ggplot2::theme(legend.position="none", panel.background=ggplot2::element_rect(fill="white",color="white"), text =ggplot2::element_text(size=15))+ggplot2::labs(x="",y="% de votos estimados - 1era vuelta")+ggplot2::scale_y_continuous(limits =c(0,50),breaks=c(10,20,30,40,50))+ggplot2::scale_color_manual(values=c("red4","red2","green4","gold2","orangered"))+ggplot2::scale_fill_manual(values=c("red4","red2","green4","gold2", "orangered"))
Platos Simple y Mixto
Ingredientes
Esta receta utiliza la misma información que la anterior: las encuestas que han salido después de las elecciones legislativas del 11 de marzo. Y los mismos priors que el Plato Simple.
Ver código
library(tidyverse)library(kableExtra)library(lubridate)#1. Importar encuestas desde GitHub #### encuestas_ulr_2018<-"https://raw.githubusercontent.com/nelsonamayad/Elecciones-presidenciales-2018/master/Elecciones%202018/encuestas2018.csv"encuestas_2018<-readr::read_csv(encuestas_ulr_2018)# Preparar data frame para calcular priorsencuestas_2018%>%dplyr::select(n,fecha,ivan_duque,gustavo_petro,sergio_fajardo,german_vargas_lleras,humberto_delacalle)%>%dplyr::filter(dplyr::between(lubridate::as_date(fecha),lubridate::as_date("2018-03-11"),lubridate::as_date("2018-05-30")))%>%tidyr::pivot_longer(cols=c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras","humberto_delacalle"), names_to ="candidato", values_to ="int_voto")%>%dplyr::mutate(nombres =dplyr::case_when(candidato=="ivan_duque"~"Ivan Duque",candidato=="gustavo_petro"~"Gustavo Petro",candidato=="sergio_fajardo"~"Sergio Fajardo",candidato=="german_vargas_lleras"~"German Vargas Lleras",candidato=="humberto_delacalle"~"Humberto de la Calle"))%>%dplyr::group_by(nombres)%>%dplyr::mutate(prior_mu=mean(int_voto,na.rm=TRUE),prior_sigma=sd(int_voto,na.rm=TRUE))%>%dplyr::distinct(prior_mu,prior_sigma)%>%knitr::kable("html", digits=1,caption ="Priors por candidato", col.names =c("Candidato","$\\mu_{prior}$","$\\sigma_{prior}$"))%>%kableExtra::kable_styling(full_width =F)%>%kableExtra::row_spec(0,bold=TRUE, background ="#FF4900", color ="white")%>%kableExtra::footnote(number =c(paste0("Encuestas disponibles: 18")))
Priors por candidato
Candidato
\(\mu_{prior}\)
\(\sigma_{prior}\)
Ivan Duque
38.1
3.3
Gustavo Petro
26.8
3.4
Sergio Fajardo
13.1
2.9
German Vargas Lleras
7.5
2.1
Humberto de la Calle
3.0
1.1
1 Encuestas disponibles: 18
Priors Plato Mixto
Pero es no es todo. Como este plato modela la relación entre todas las caraterísticas de las encuestas, necesita priors para las varianzas y correlaciones entre todos los parámetros.
AdvertenciaOjo, lo que sigue es algo técnico
El plato mixto utiliza un prior específico con la distribución Lewandowski-Kurowicka-Joe (LKJ para sus amigos), que permite definir con un sólo parámetro \(\eta\) la diagnonal de la matriz de correlación.
Utilizando el prior \(\eta=2\) las correlaciones están débilmente informadas y son escépticas de niveles extremos como -1 (perfecta correlación negativa) o 1 (perfecta correlación positiva). Ese es el prior que recomiendan el manual de Stan y el texto McElreath para situaciones en las que esas relaciones no se conocen muy bien.
No voy a decir más sobre esto excepto que este truco permite lo que el Plato Mixto busca hacer: aprovechar mejor la poca información que hay.
Receta
Esta receta tiene la misma base que la anterior. La proporción de votos para cada candidato sale de modelo lineal sobre características observables de las encuestas: 1) el tamaño de la muestra de cada encuesta (m), 2) el márgen de error de la encuesta (e), 3) los días que pasaron entre la encuesta y la estimación (d), 4) una dummy para el tipo de encuesta (telefónica o presencial) (tipo).
La diferencia entre esta receta y la anterior es añadir (\(\beta_{encuestadora[i]}\)) a los coeficientes de las otras variables explicativas. Suena simple pero no lo es: implica incluir una matriz de varianza/covarianza que describe cómo se relaciona la distribución posterior de cada parámetro con los otros (ver capítulo 13 de Statistical Rethinking).
Preparación
Este es el modelo con los respectivos priors para cada parámetro. Nuevamente, los únicos priors informados son los que determinan el parámetro que captura el promedio y desviación estándar de cada candidato. El otro prior clave es el que va en la matriz de correlación LKJ.
Nunca fui muy hábil en álgebra lineal, así que esto va con uno que otro detalle innecesario y de pronto un horror en notación:
library(tidyverse)library(lubridate)# Alistamiento ####encuestas_simple_2018<-readr::read_csv("https://raw.githubusercontent.com/nelsonamayad/Elecciones-presidenciales-2018/master/Elecciones%202018/encuestas2018.csv")%>%# Seleccionar candidatos que encabezan las encuestasdplyr::select(n,fecha,encuestadora,ivan_duque,gustavo_petro,sergio_fajardo,german_vargas_lleras, humberto_delacalle, m_error=margen_error, muestra_int_voto,tipo)%>%# Pivotear los datostidyr::pivot_longer(cols =c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras", "humberto_delacalle"), names_to ="candidato", values_to ="int_voto")%>%# Seleccionar solo las encuestas hechas en 2018 antes de la primea vueltadplyr::filter(dplyr::between(as.Date(fecha, tz="GMT"),as.Date('2018-03-11', tz="GMT"),as.Date('2018-05-19', tz="GMT")))%>%# Crear algunas variablesdplyr::mutate(e_max =int_voto+m_error, e_min =int_voto-m_error, fecha =as.Date(fecha), candidato =factor(candidato, levels=c("ivan_duque","gustavo_petro","sergio_fajardo","german_vargas_lleras","humberto_delacalle")), enc =factor(encuestadora), encuestadora=as.numeric(enc))%>%#Crear variable duracion:dplyr::mutate(dd =as.Date(as.character(lubridate::today()), format="%Y-%m-%d")-as.Date(as.character(fecha), format="%Y-%m-%d"))%>%dplyr::mutate(dd =as.numeric(dd))%>%dplyr::mutate(dd =100*(dd/sum(dd)))%>%dplyr::mutate(tipo=ifelse(tipo=="Presencial",1,0))## Crear data frames por candidato: ####id_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="ivan_duque", !is.na(int_voto))gp_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="gustavo_petro", !is.na(int_voto))sf_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="sergio_fajardo", !is.na(int_voto))gvl_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="german_vargas_lleras", !is.na(int_voto))hdlc_2018_simple<-encuestas_simple_2018%>%dplyr::filter(candidato=="humberto_delacalle", !is.na(int_voto))
Estimación
El plato mixto también se prepara con RStan, y en este caso voy a usar al candidato Iván Duque como ejemplo.
El código es miedoso, y tuve que verificarlo varias veces con el paquete rethinking de McElreath. Pero logra su cometido.
El modelo utiliza los priors \(\small\mu_{candidato}=38\), \(\small\sigma_{candidato}=3\) y para la matriz de correlaciones LKJ \(\small\eta=2\). Toda la receta va en el siguiente objeto duque.stan:
Ver código
data {int<lower=1> N; // here N = 18int<lower=1> J; // here J = 7 (encuestadoras)vector[N] int_voto;array[N] int<lower=0, upper=1> tipo; // if truly binary/ordinal you can constrain tightervector[N] dd;vector[N] m_error;array[N] int muestra_int_voto; // integer predictorarray[N] int<lower=1, upper=J> encuestadora;}parameters {// group-level coefficients by encuestadora (J=7)vector[J] a_encuestadora;vector[J] b1_encuestadora;vector[J] b2_encuestadora;vector[J] b3_encuestadora;vector[J] b4_encuestadora;// population-level meansreal a;real b1;real b2;real b3;real b4;// hierarchical covariance componentsvector<lower=0>[5] s_encuestadora; // SDs for (a, b1, b2, b3, b4)corr_matrix[5] Rho;// observation noisereal<lower=0> s;}transformed parameters {vector[N] m;// linear predictor (same as your loop, vectorized via indexing) m = a_encuestadora[encuestadora] + b1_encuestadora[encuestadora] .* to_vector(muestra_int_voto) + b2_encuestadora[encuestadora] .* m_error + b3_encuestadora[encuestadora] .* dd + b4_encuestadora[encuestadora] .* to_vector(tipo);}model {// priors Rho ~ lkj_corr(2); s ~ cauchy(0, 5); s_encuestadora ~ cauchy(0, 5); a ~ normal(38, 4); b1 ~ normal(0, 10); b2 ~ normal(0, 10); b3 ~ normal(0, 10); b4 ~ normal(0, 10);// hierarchical model for encuestadora-specific coefficient vectors {vector[5] MU = [a, b1, b2, b3, b4]';matrix[5, 5] Sigma = quad_form_diag(Rho, s_encuestadora);array[J] vector[5] YY;for (j in1:J) { YY[j] = [ a_encuestadora[j], b1_encuestadora[j], b2_encuestadora[j], b3_encuestadora[j], b4_encuestadora[j] ]'; } YY ~ multi_normal(MU, Sigma); }// likelihood int_voto ~ normal(m, s);}generated quantities {real dev; dev = -2 * normal_lpdf(int_voto | m, s);}
El Plato Mixto necesita mucho más tiempo para cocinarse, pero al final sale. Aunque duque.stan tiene muchas divergencias iniciales en el muestreo, el plato sale del horno sin quemarse.
Ver código
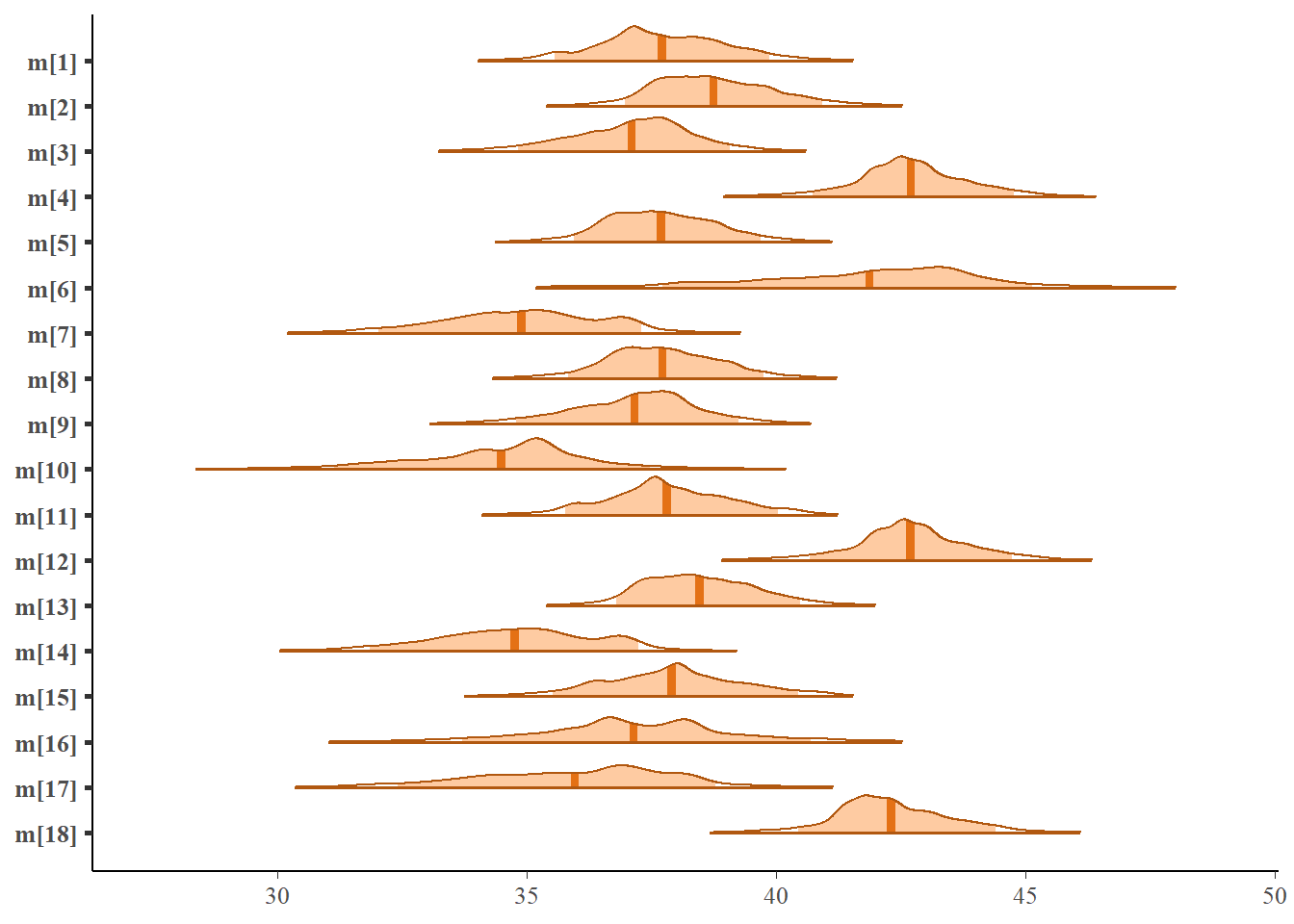
library(bayesplot)bayesplot::color_scheme_set("orange")# Crear matriz de muestras de la distribucion posteriorposterior_mixto<-posterior::as_draws_matrix(duque_fit)#Trace plot para los parametros de interesbayesplot::mcmc_trace(posterior_mixto,pars=ggplot2::vars(tidyselect::starts_with("m[")))
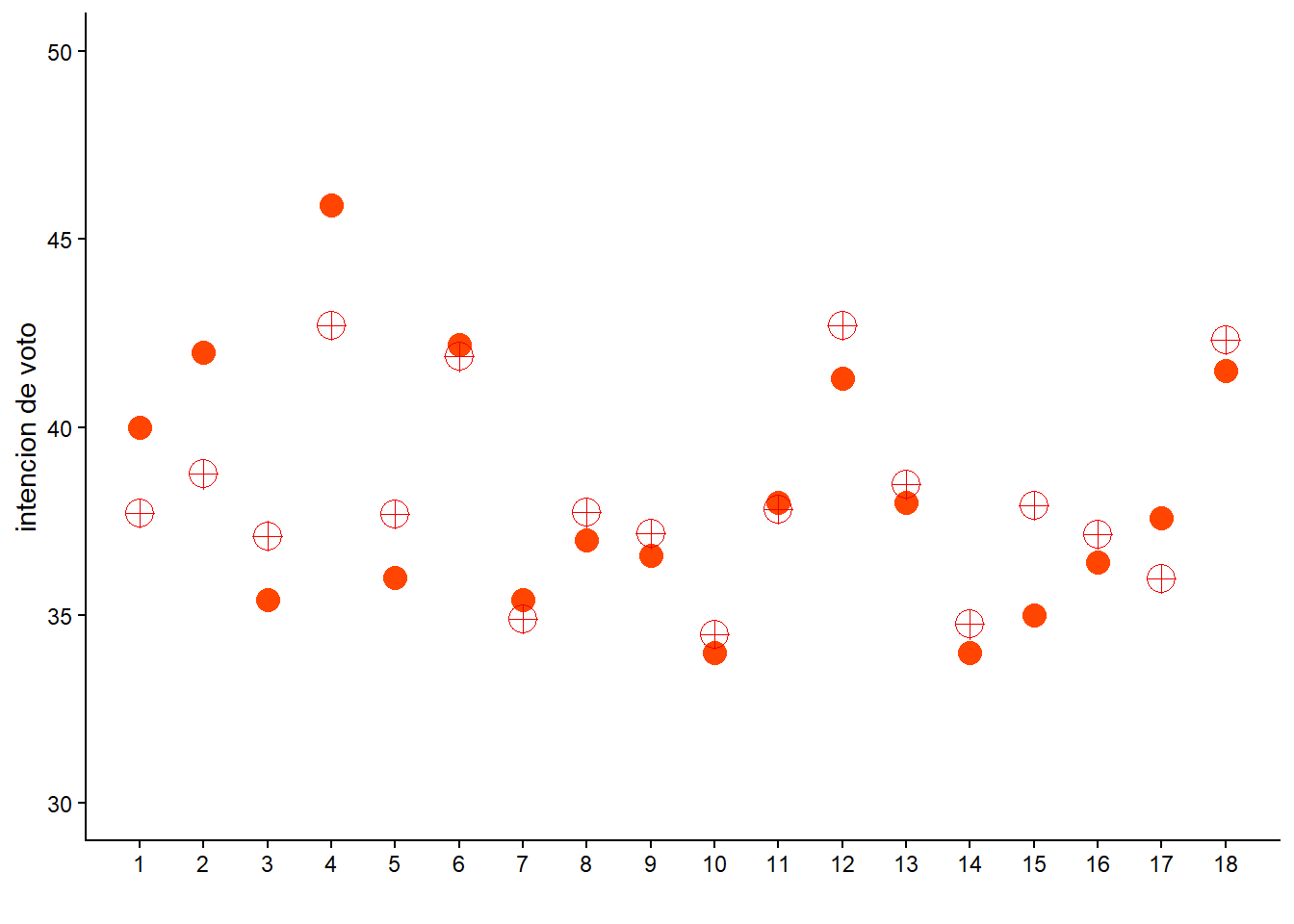
Plato Mixto: Parámetros vs Observaciones
El resultado es un plato que sabe mejor que el simple. Puede que el sabor sea demasiado bueno (i.e. overfitting).
Para los que tuvieron la paciencia de bajar hasta acá, va un premio: los valores observados para Iván Duque en las encuestas (en naranja) vs. los valores estimados por el plato mixto (en rojo).
Stan Development Team. 2017. RStan: the R interface to Stan. R package version 2.16.2. http://mc-stan.org
Stan Development Team. 2017. ShinyStan: Interactive Visual and Numerical Diagnostics and Posterior Analysis for Bayesian Models. R package version 2.4.0. http://mc-stan.org