library(tidyverse)
library(RColorBrewer)
library(here)
# Parametros ####
shape_entrada_2022 <- c(22,4,23,16,17,21,12,5,18,19)
colors_entrada_2022 <- c(
"Alejandro Gaviria" = rgb(50,205,50, maxColorValue = 255),
"Sergio Fajardo" = rgb(31,161,46, maxColorValue = 255),
"Juan Manuel Galan" = rgb(213,48,62, maxColorValue = 255),
"Ingrid Betancourt" = rgb(14,185,11, maxColorValue = 255),
"Alex Char" = rgb(228,0,120, maxColorValue = 255),
"David Barguil" = rgb(0,97,169, maxColorValue = 255),
"Enrique Peñalosa" = rgb(0,139,139, maxColorValue = 255),
"Federico Gutierrez" = rgb(0,0,255, maxColorValue = 255),
"Oscar I. Zuluaga" = rgb(30,144,255, maxColorValue = 255),
"Gustavo Petro" = rgb(128,0,128, maxColorValue = 255),
"Rodolfo Hernandez" = rgb(247,190,10, maxColorValue = 255),
"Voto en blanco" = rgb(32,33,36, maxColorValue = 255)
)
# Calentao resultados ####
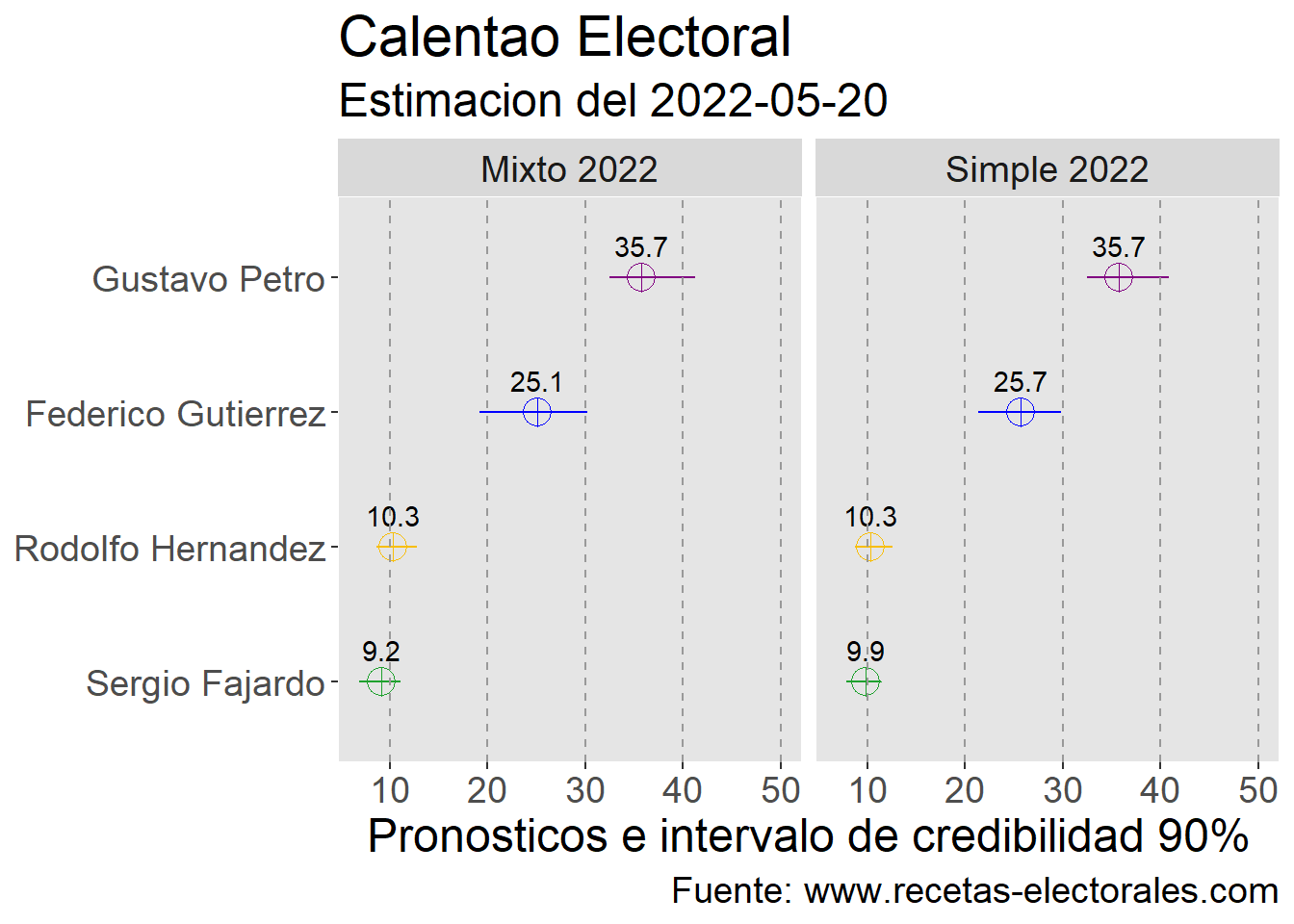
readr::read_csv(here("elecciones", "2022-colombia","2022-04-24-calentao",
"calentao-2022_resultados.csv")) %>%
#Predicciones
dplyr::group_by(modelo) %>%
dplyr::summarise(m_all = mean(value),
p10 = quantile(value,0.1),
p90 = quantile(value,0.9)) %>%
dplyr::mutate(candidato = stringr::str_sub(modelo, start = 1L,end = 2L),
plato = ifelse(stringr::str_sub(modelo, start = 4L,end=8L)=="mixto", "Mixto 2022","Simple 2022")) %>%
dplyr::left_join(tibble::tribble(~candidato,~nombre,
"gp","Gustavo Petro",
"fg","Federico Gutierrez",
"sf","Sergio Fajardo",
"rh","Rodolfo Hernandez"),
by=c("candidato")) %>%
# Exclude IB
dplyr::filter(!is.na(nombre)) %>%
#Grafico
ggplot2::ggplot(ggplot2::aes(x=nombre %>% reorder(m_all),color=nombre))+
ggplot2::geom_point(ggplot2::aes(y=m_all), shape=10, size=5)+
ggplot2::geom_text(ggplot2::aes(y=m_all, label=m_all %>% round(digits=1)),color="black",vjust=-1)+
ggplot2::geom_linerange(ggplot2::aes(ymin=p10,ymax=p90))+
ggplot2::geom_hline(yintercept=seq(10,50,10),linetype="dashed",color="grey60")+
ggplot2::coord_flip()+
ggplot2::facet_wrap(~plato)+
ggplot2::scale_color_manual(values=colors_entrada_2022)+
ggplot2::theme(legend.position="none",
text = ggplot2::element_text(size=18),
panel.grid = ggplot2::element_blank(),
panel.background=ggplot2::element_rect(fill="grey90", color="white")
)+
ggplot2::labs(x=NULL,
y="Pronosticos e intervalo de credibilidad 90%",
title = "Calentao Electoral",
subtitle = "Estimacion del 2022-05-20",
caption="Fuente: www.recetas-electorales.com"
)