“The existence of a problem in knowledge depends on the future being different from the past, while the possibility of a solution of the problem depends on the future being like the past.” – Frank Knight
El postre busca lograr lo que los anteriores no pudieron: estimar qué tan probable es que gane uno u otro candidato. Para hacer eso el postre le aplica una transformación sencillita al Plato Simple: en vez de servir dos recetas por candidato, se sirve un solo postre logístico para ambos. Esto genera un pronóstico probabilístico para la segunda vuelta.
¿Por qué hacerlo así? Porque según las encuestas la victoria es clara para Duque: todas coinciden en que el candidato de la coalición de derecha obtiene una mayor proporción de votos que su contrincante. Es más, el resultado del Plato Mixto, al que mejor le fue en la primera vuelta, si es aplicado a las encuestas que salieron después del 27 de mayo da como resultado que Duque obtendrá 51% de la votación, con un rango intervalo HPD de 95% de entre 46% y 57%, y Petro obtendría 37%, con un rango HPD de 95% entre 34% y 41%. Así que en vez de decir lo obvio, nos vamos por lo menos evidente, aunque sea más difícil de masticar.
Postre Logístico
Este postre recoge la probabilidad de que @IvanDuque sea presidente, estimada por el modelo que se describe abajo.
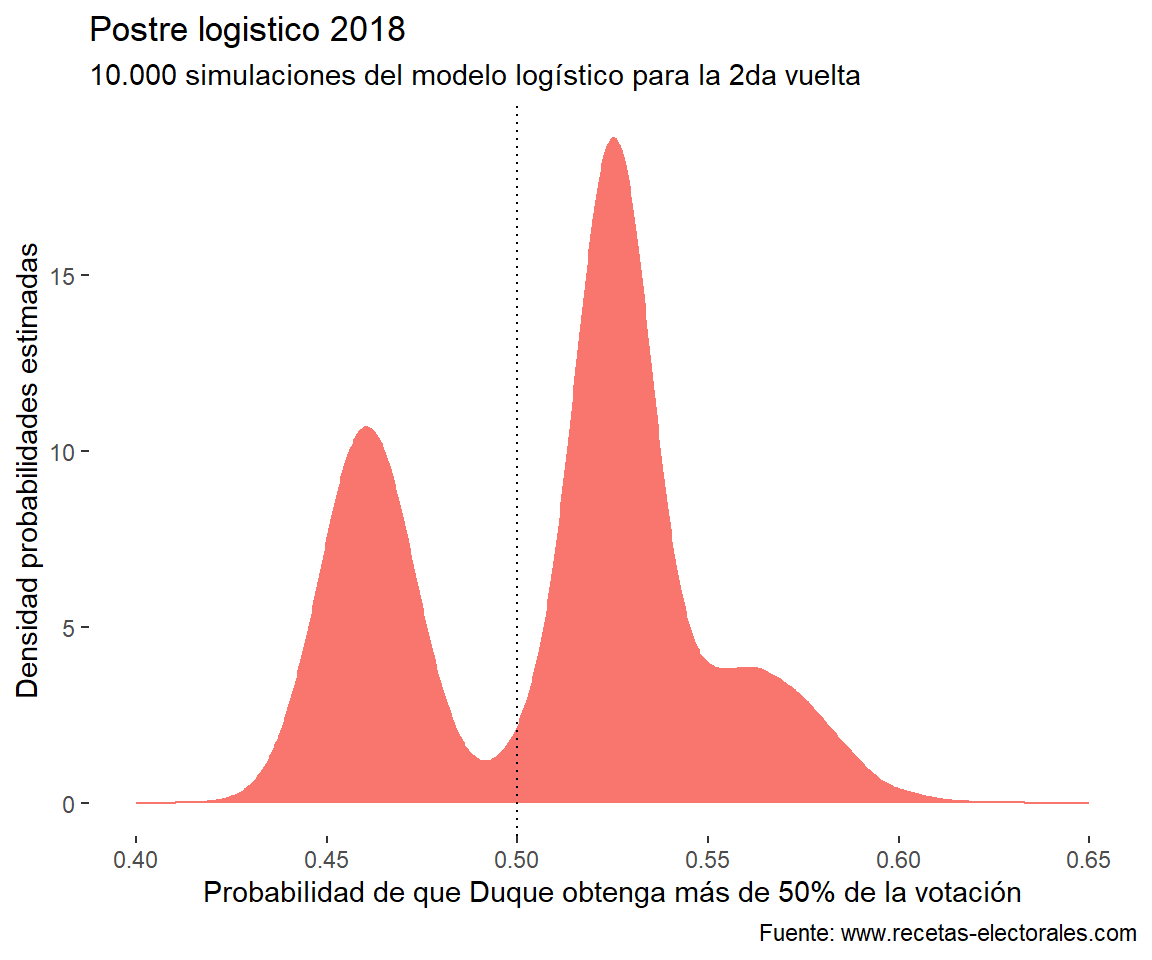
Estas probabilidades salen de sacar muchas simulaciones de cada uno de los parámetros del modelo estimado. El resultado es una densidad de la probabilidad de que Duque obtenga más de 50% de la votación. La distribución parece bimodal porque unas encuestas le dan menos de 50% de la votación a Duque, pero el grueso dice lo contrario: en 20% de las simulaciones el modelo estima que Duque gana con más o menos 53% de probabilidad.
ImportanteUn pronóstico probabilístico
@IvanDuquetiene más o menos 65% de probabilidad de obtener más del 50% de la votación.
Ver código
library(tidyverse)library(posterior)postre_2018_logis_fit|>posterior::as_draws_df()|>dplyr::transmute(dplyr::across(dplyr::starts_with("a_raw["), ~stats::plogis(a_bar+s*.x)))|>tidyr::pivot_longer(dplyr::everything(), names_to ="encuestadora", values_to ="estimates")|>ggplot2::ggplot(ggplot2::aes(x=estimates))+ggplot2::geom_density(ggplot2::aes(x=estimates,fill="orangered3",color="grey60"))+ggplot2::geom_vline(xintercept=0.5,linetype="dotted")+ggplot2::labs(x="Probabilidad de que Duque obtenga más de 50% de la votación",y="Densidad probabilidades estimadas", title="Postre logistico 2018", subtitle="10.000 simulaciones del modelo logístico para la 2da vuelta", caption ="Fuente: www.recetas-electorales.com")+ggplot2::theme(legend.position ="none", panel.background =ggplot2::element_blank())+ggplot2::xlim(0.4,0.65)
Postre logistico 2018
Ingredientes
Los únicos ingredientes de esta receta son las encuestas que han salido desde la primera vuelta. Como priors se toman los promedios y desviaciones estándar de cada candidato.
Ver código
library(tidyverse)library(lubridate)# 1. Encuestas 2018 ####encuestas_ulr_2018<-"https://raw.githubusercontent.com/nelsonamayad/Elecciones-presidenciales-2018/master/Elecciones%202018/encuestas2018.csv"encuestas_2018<-readr::read_csv(encuestas_ulr_2018)# 2. Alistamiento de los datosencuestas_postre_2018<-encuestas_2018%>%# Seleccionar candidatos que encabezan las encuestasdplyr::select(n,fecha,encuestadora,ivan_duque,gustavo_petro, m_error=margen_error, muestra_int_voto,tipo, municipios)%>%# Seleccionar solo las encuestas hechas despues de la primera vueltadplyr::filter(lubridate::as_date(fecha)>=lubridate::as_date("2018-05-31"))%>%# Crear algunas variablesmutate(id =ivan_duque*muestra_int_voto/100, gp =gustavo_petro*muestra_int_voto/100, tipo =ifelse(tipo=="Presencial",1,0), fecha =as.Date(fecha), enc =factor(encuestadora), encuestadora=as.numeric(enc))%>%#Crear variable duracion:dplyr::mutate(dd =as.Date(as.character(lubridate::today()), format="%Y-%m-%d")-as.Date(as.character(fecha), format="%Y-%m-%d"))%>%dplyr::mutate(dd =as.numeric(dd))%>%dplyr::mutate(dd =100*(dd/sum(dd)))%>%dplyr::mutate(dplyr::across(c("id","gp"),~round(.,digits=0)))
Receta
Este postre modela directamente las encuestas como una distribución binomial donde cada encuesta es un ensayo:
\[ N^{Duque}_i \sim \textrm{Binomial}(N_i, \pi^{Duque}_i) \] donde \(N_i\) es la muestra de cada encuesta y \(\pi^{Duque}_i\) es la proporción de la intención de voto para Iván Duque.
Ahora, la proporción de intención de voto para Duque \(\pi^{Duque}_i\) se determina a través de una función logística (log-link function) y, como es costumbre en este recetario, efectos aleatorios por encuestadora así:
Este es el postre completo, con los priors del caso: \[ N^{Duque}_i \sim \textrm{Binomial}(N_i, \pi^{Duque}_i) \]\[\textrm{logit} (\pi^{Duque}_i) = \alpha_{encuestadora}\]\[\small\alpha_{encuestadora} \sim Normal(\alpha,\sigma) \]\[\small\alpha \sim Normal(50, 5) \]\[\small\sigma \sim HalfCauchy(0,5) \]
Estimación
Este es el modelo en el siempre espeluznante código de RStan:
Ver código
data {int<lower=1> N;int<lower=1> N_encuestadora;// successesarray[N] int<lower=0> id;// trialsarray[N] int<lower=0> muestra_int_voto;// pollster index (1..N_encuestadora)array[N] int<lower=1, upper=N_encuestadora> encuestadora;}parameters {real a_bar; // population mean logitvector[N_encuestadora] a_raw; // non-centered pollster effectsreal<lower=0> s; // between-encuestadora SD (logit scale)}transformed parameters {vector[N_encuestadora] a; // pollster-specific logitsvector[N] eta; // linear predictor per observation a = a_bar + s * a_raw; eta = a[encuestadora];}model { a_bar ~ normal(0, 0.20); s ~ student_t(3, 0, 0.5); // half-t via <lower=0> a_raw ~ std_normal();// Likelihood id ~ binomial_logit(muestra_int_voto, eta);}generated quantities {real dev; dev = -2 * binomial_logit_lpmf(id | muestra_int_voto, eta);}
Además de la siempre abstrusa representación del código en RStan, en este postre incluyo una alternativa que de paso le hace bombo al paquete rethinking que preparó uno de los mejores cocineros: Richard McElreath.
La especificación del modelo en el código del paquete rethinking, que traduce a un lenguaje más amable el código de RStan, se ve así:
Ver código
library(rethinking)# Modelo logístico en ulam:postre_ulam<-rethinking::ulam(alist(id~dbinom(muestra_int_voto, p),logit(p)<-a[encuestadora],a[encuestadora]~dnorm(a_bar, s),a_bar~dnorm(0, 0.20),s~dexp(1)), data =list( id =encuestas_postre_2018$id, muestra_int_voto =encuestas_postre_2018$muestra_int_voto, encuestadora =encuestas_postre_2018$encuestadora), control=list(adapt_delta=0.96), iter=4000, warmup=1000, chains=4, cores=2)
Referencias
Este proyecto de Pierre-Antoine Kremp, para las presidenciales en EEUU de 2016, fue la inspiración para estas recetas.
McElreath, R. (2015). Statistical Rethinking. Texts in Statistical Science. Bendito sea Richard McElreath por este texto.