Un modelo generativo completo para la primera vuelta
Autor/a
Afiliación
Recetas Electorales
Análisis independiente
Fecha de publicación
28 de enero de 2026
Fecha de última modificación
19 de mayo de 2026
“Failure is a favor to the future.” –Rita Dove
Introduciendo el Ajiaco2
El Ajiaco2 es un modelo probabilístico que las Recetas Electorales han tratado de preparar desde hace 5 años. Es complejo, pero funciona divínamente. Es el motor inferencial para la primera vuelta.
Es un modelo que procesa simultáneamente todas las encuestas como un proceso Dirichlet-multinomial, de manera que se preserven las cotas de que los posibles candidatos no tengan probabilidades absurdas de pasar a la segunda vuelta. Esto es mucho más difícil de lo que parece, y hay que hacer ciertos supuestos importantes como imputaciones de los conteos de las encuestas con base en las proporciones reportadas en las fichas técnicas. De cualquier forma, el nuevo Ajiaco2 supera las limitaciones de la receta de 2022 y se puede servir completo.
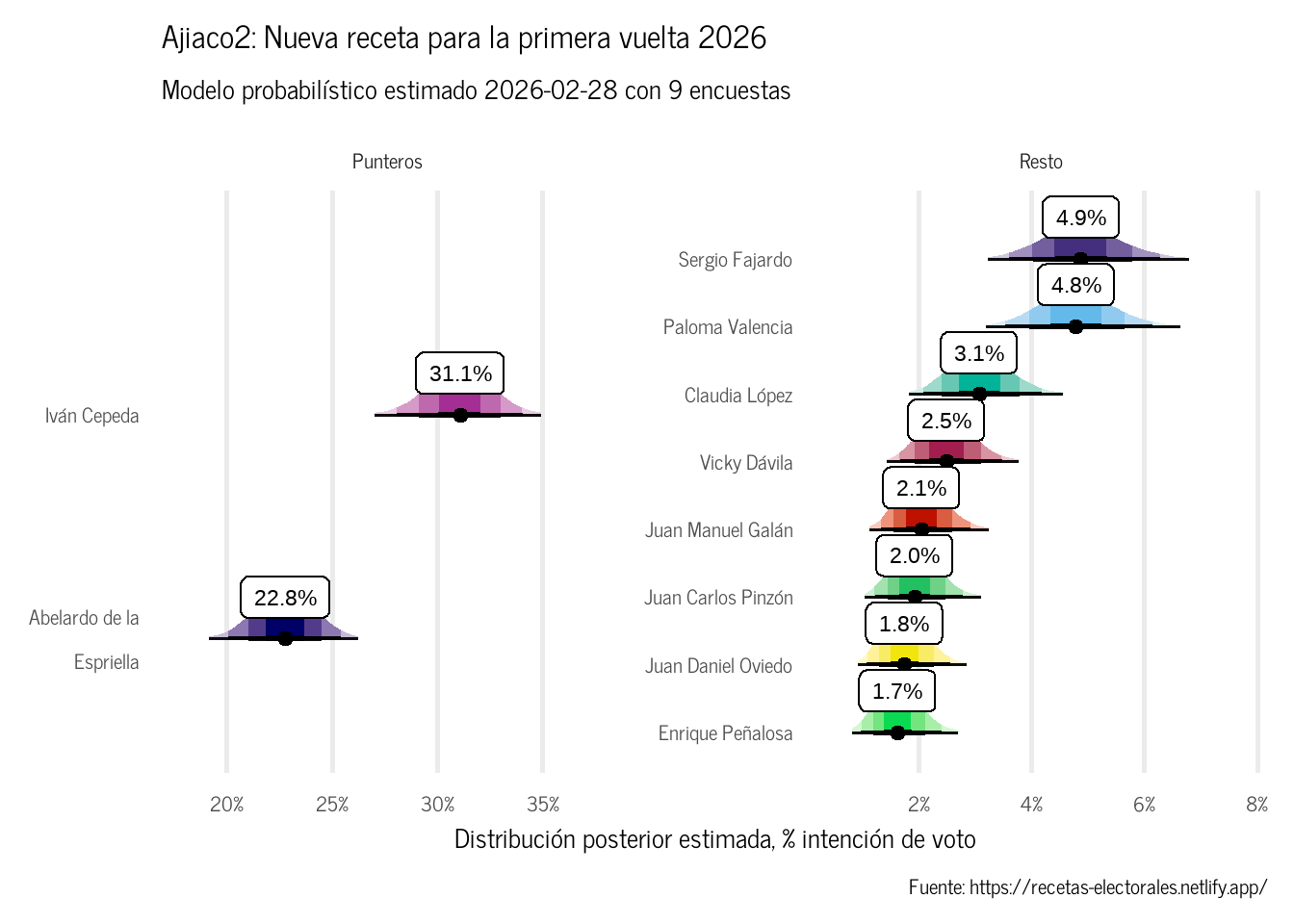
Veamos los resultados de la más reciente estimación del Ajiaco2Figura 1 para los candidatos a la primera vuelta luego de las consultas del 13 de marzo:
Ver código
# Graph posterior ####ajiaco2_fit|>posterior::as_draws_df()|>tibble::as_tibble()|>dplyr::rename_with(~paste0("p_", colnames(conteos_2026)), .cols =paste0("p[", seq_along(colnames(conteos_2026)), "]"))|>tidyr::pivot_longer(cols =dplyr::starts_with("p"), names_to ="candidato", values_to ="prop")|>dplyr::mutate(candidato =stringr::str_sub(candidato, start =8L))|>dplyr::group_by(candidato)|>dplyr::mutate(candidato_m =mean(prop), .group_by ="drop")|># Nombresdplyr::left_join(candidatos_2026, by =c("candidato"="cod"))|># Quitar ruidodplyr::filter(candidato!="ruido")|>ggplot2::ggplot(ggplot2::aes(x =prop, y =reorder(nombre, candidato_m)))+ggdist::stat_dist_slabinterval(ggplot2::aes( fill =color_cand, fill_ramp =ggplot2::after_stat(level)), .width =c(0.5, 0.8, 0.95, 0.99), interval_alpha =0.95, show.legend =c(fill =FALSE, fill_ramp =TRUE, size =FALSE))+ggdist::stat_pointinterval(ggplot2::aes(label =scales::percent(candidato_m, accuracy =0.1)), geom ="label", .width =0, vjust =-0.5, fill ="white", color ="black")+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_y_discrete(labels =scales::label_wrap(20))+ggplot2::scale_fill_identity(na.translate =FALSE)+ggdist::scale_fill_ramp_discrete( name ="Credible interval", range =c(0.25, 1), breaks =c(0.5, 0.8, .95, 0.99), labels =c("50%", "80%", "95%", "99%"), na.translate =FALSE)+ggplot2::labs( title ="Ajiaco2: Modelo probabilístico para la primera vuelta 2026", subtitle =paste0("Estimado ", Sys.Date(), " con ", dplyr::n_distinct(encuestas_2026$encuesta_id)," encuestas"), caption ="Fuente: https://recetas-electorales.netlify.app/", x ="Distribución posterior estimada, % intención de voto", y =NULL)+ggplot2::theme_minimal(base_size =20)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.major.y =ggplot2::element_blank(), panel.grid.minor =ggplot2::element_blank(), legend.position ="none")
Figura 1: Ajiaco2
Evolución acumulada
La siguiente animación muestra cómo el Ajiaco2 actualiza sus estimaciones a medida que llegan nuevas encuestas, desde marzo hasta mayo 2026.
Ajiaco2: evolución acumulada de la distribución posterior
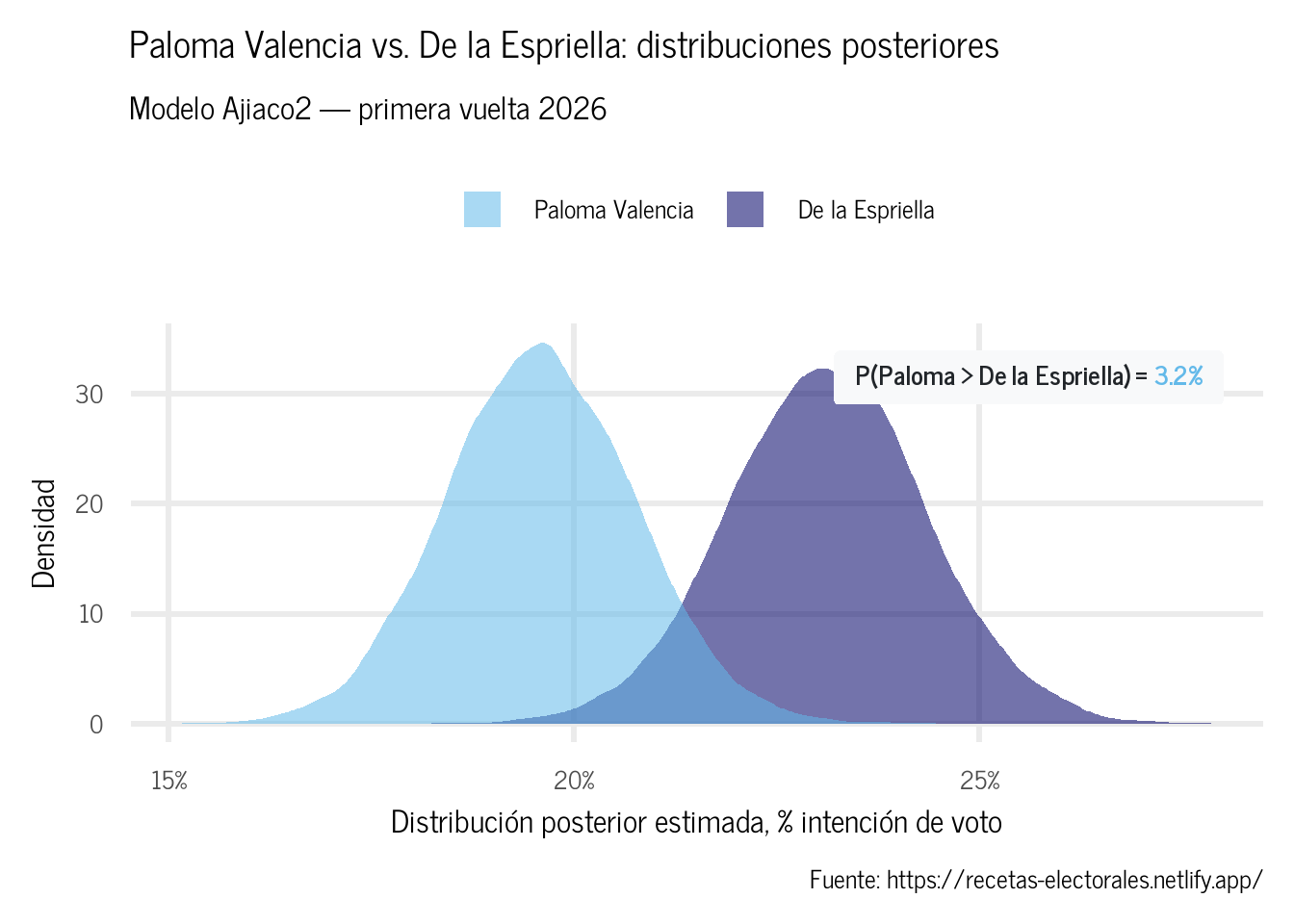
Valencia o De la Espriella? Las probabilidades
Una ventaja del enfoque bayesiano es que las comparaciones directas entre candidatos son inmediatas, solo hay que calcular la fracción de muestras en los que la proporción de un candidato supera la del otro. No hay prueba de hipótesis, ni p-values, ni carreta frecuentista: solo probabilidades posteriores.
Según el Ajiaco2 a 19 Mayo 2026, la probabilidad posterior de que Paloma Valencia obtenga más votos que De la Espriella en primera vuelta es 3.2%.
Ver código
library(ggtext)draws_comp|>dplyr::select(p_cand_pv, p_cand_adle, .draw)|>tidyr::pivot_longer( cols =c(p_cand_pv, p_cand_adle), names_to ="candidato", values_to ="prop")|>dplyr::mutate( color_cand =dplyr::case_when(candidato=="p_cand_pv"~"#63B9E9",candidato=="p_cand_adle"~"#000066"))|>ggplot2::ggplot(ggplot2::aes(x =prop, fill =color_cand))+ggplot2::geom_density(alpha =0.55, color =NA)+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_fill_identity( guide ="legend", labels =c("#63B9E9"="Paloma Valencia", "#000066"="De la Espriella"), breaks =c("#63B9E9", "#000066"))+ggtext::geom_richtext( data =tibble::tibble(x =Inf, y =Inf),ggplot2::aes( x =x, y =y, label =sprintf("<b>P(Paloma > De la Espriella) = <span style='color:#63B9E9'>%.1f%%</span></b>",prob_pv_gt_adle*100)), inherit.aes =FALSE, hjust =1.1, vjust =1.5, size =7, family ="news-cycle", fill ="#F8F9FA", color ="#212529", label.color =NA, label.padding =ggplot2::unit(c(0.4, 0.6, 0.4, 0.6), "lines"))+ggplot2::labs( title ="Paloma Valencia vs. De la Espriella: distribuciones posteriores", subtitle ="Modelo Ajiaco2 — primera vuelta 2026", x ="Distribución posterior estimada, % intención de voto", y ="Densidad", fill =NULL, caption ="Fuente: https://recetas-electorales.netlify.app/")+ggplot2::theme_minimal(base_size =24)+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle"), panel.grid.minor =ggplot2::element_blank(), legend.position ="top")
Figura 2: Distribuciones posteriores de Paloma Valencia y De la Espriella.
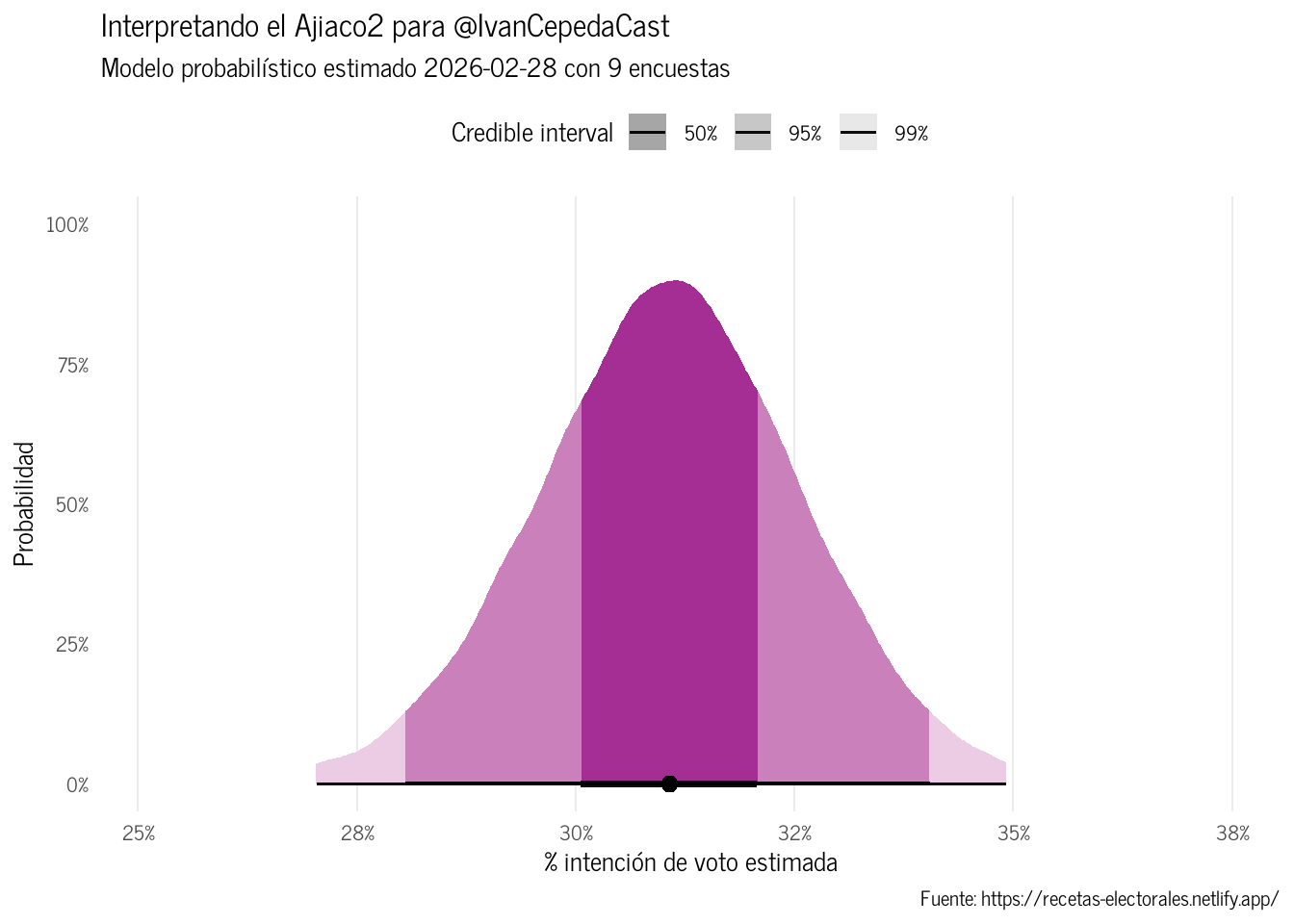
Descifrando porcentajes y probabilidades en el Ajiaco2
Es relativamente fácil interpretar el Ajiaco2, así que ilustremos para uno de los punteros Figura 3. Cada curva muestra la distribución posterior de la proporción de voto del candidato, estimada a partir del modelo Dirichlet-multinomial. Por ejemplo, para @IvanCepedaCast la mayor densidad se concentra alrededor del 36%, lo que indica que este es el valor más compatible con las encuestas observadas. El modelo sugiere que la probabilidad posterior de que la intención de voto sea inferior al 25% es prácticamente nula y que sea mayor a 50%, lo que necesitaría un candidato para ganar en primera vuelta, es también nula.
El intervalo creíble del 50% pone la intención de voto entre 34% y 37%, mientras que el intervalo de 95% se extiende desde cerca de 31% hasta 40%, lo que refleja la incertidumbre que resulta de la heterogeneidad de las encuestas disponibles.
Ver código
# Graph posterior ####ajiaco2_fit|>posterior::as_draws_df()|>tibble::as_tibble()|>dplyr::rename_with(~paste0("p_", colnames(conteos_2026)), .cols =paste0("p[", seq_along(colnames(conteos_2026)), "]"))|>tidyr::pivot_longer(cols =dplyr::starts_with("p"), names_to ="candidato", values_to ="prop")|>dplyr::mutate(candidato =stringr::str_sub(candidato, start =8L))|># Nombresdplyr::left_join(candidatos_2026, by =c("candidato"="cod"))|>dplyr::filter(candidato%in%c("ic"))|>ggplot2::ggplot(ggplot2::aes(x =prop))+ggdist::stat_dist_slabinterval(ggplot2::aes( fill =color_cand, fill_ramp =ggplot2::after_stat(level)), .width =c(0.5, 0.95, 0.99), interval_alpha =0.95, show.legend =c(fill =FALSE, fill_ramp =TRUE, size =FALSE))+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_y_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_fill_identity(na.translate =FALSE)+ggdist::scale_fill_ramp_discrete( name ="Credible interval", range =c(0.25, 1), breaks =c(0.5, .95, 0.99), labels =c("50%", "95%", "99%"), na.translate =FALSE)+ggplot2::labs( title ="Interpretando el Ajiaco2 para @IvanCepedaCast", subtitle =paste0("Modelo probabilístico estimado", Sys.Date(), " con ", dplyr::n_distinct(encuestas_2026$encuesta_id)," encuestas"), caption ="Fuente: https://recetas-electorales.netlify.app/", x ="% intención de voto estimada", y ="Probabilidad")+ggplot2::theme_minimal()+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle", size =20), panel.grid.major.y =ggplot2::element_blank(), panel.grid.minor =ggplot2::element_blank(), legend.position ="top")
Figura 3: Interpretando el Ajiaco2
TipÑapa: Ajiaco2App para explorar cada candidato
El ajiaco viene con ñapa para explorar interactivamente el modelo Ajiaco2. Selecciona un candidato y un umbral de intención de voto para ver probabilidades posteriores.
Retrovisor: El Ajiaco de 2022 quedó aguado. ¿Qué falló?
En 2022 salió la primera versión de Ajiaco, que en su momento buscaba solucionar un problema técnico complejo en el análisis de encuestas: ¿Cómo se pueden representar correctamente las probabilidades de \(N\) candidatos que compiten en la primera vuelta? Para solucionar el problema era necesario usar distribuciones de probabilidad un tanto complejas; tal vez más complicado aún era determinar la parametrización de esas funciones.
El Ajiaco en 2022 buscó estimar simuláneamente la proporción de votos para cada candidato teniendo en cuenta las proporciones de voto blanco e indeciso, y trató de proyectar la incertidumbre que hay en cada votación sin romper el techo que mantiene acotadas las proporciones para que nunca sumen menos de cero o más de cien por ciento.
Fracasó: el Ajiaco de 2022 quedó aguado. No logró lo que pretendía y cometió muchos errores, algunos imperdonables. El modelo avanzó en el uso de la función correcta, una Dirichlet, pero no usó las observaciones a nivel cada encuesta directamente; además ignoró la varianza muestral, las diferencias por encuestadora y el paso del tiempo. El modelo usó estimaciones de promedios por candidato para simular a cada candidato. El muestreo MCMC era redundante y no había propagación de la incertidumbre como se pensaba. Metodológicamente no fue un modelo predictivo inferencial porque fijaba arbitrariamente el tamaño de muestra (\(N=100\)) de resultados de las encuestas existentes.
Mea culpa. Estas cosas son dificiles de hacer y se hizo lo que se pudo en 2022. Pero como dice la poeta Rita Doves, el error del pasado al menos nos ayudó a solucionar el problema del presente.
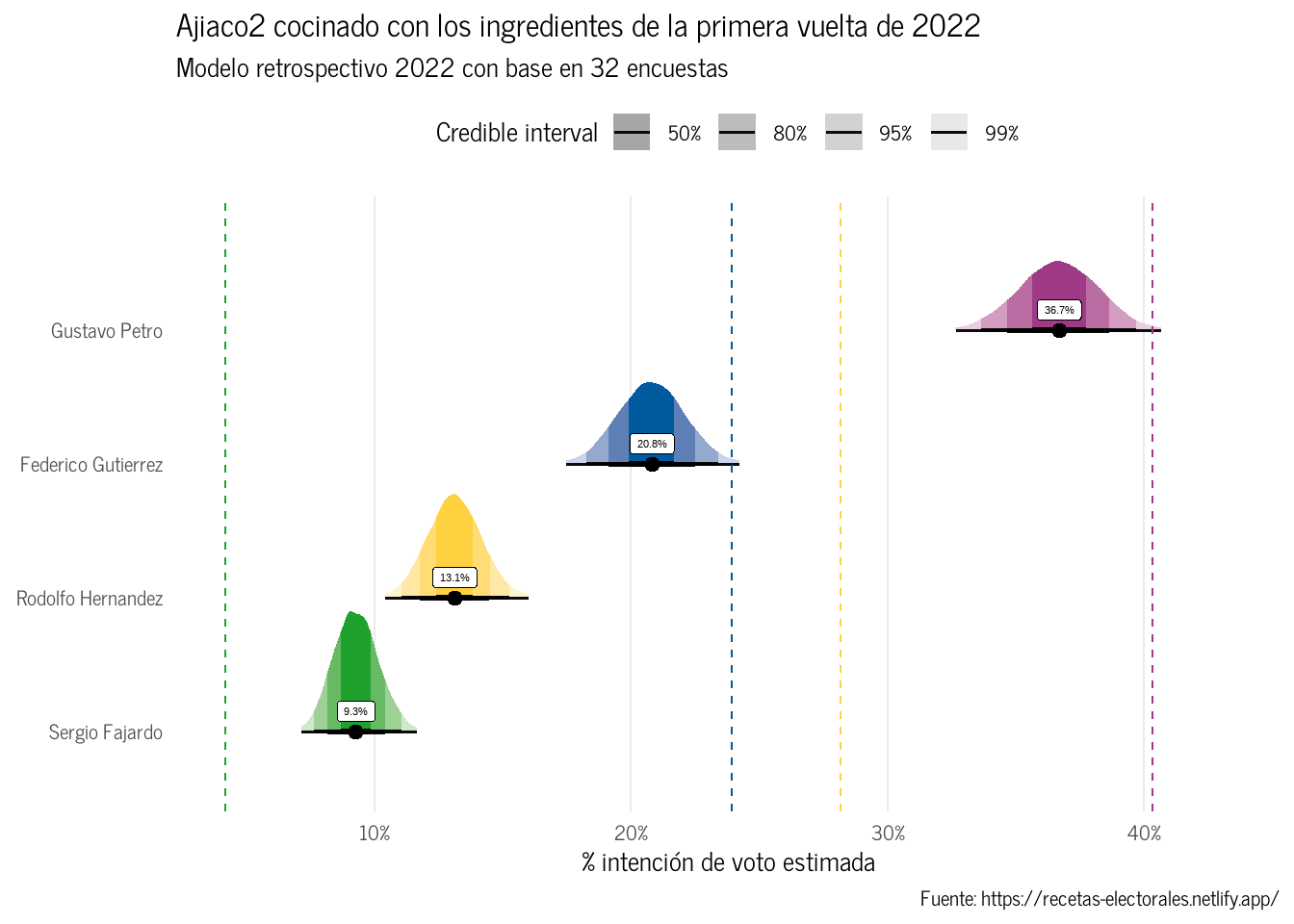
AdvertenciaAjiaco2 cocinado con los ingredientes de 2022
El modelo corregido se puede aplicar a la primera vuelta de 2022. El resultado Figura 4 es similar: Las encuesta no detectaron la subida de Rodolfo Hernandez por la veda.
Ver código
# ggdist ####ajiaco2_retro2022_fit|>posterior::as_draws_df()|>tibble::as_tibble()|>dplyr::rename_with(~paste0("p_", colnames(conteos_2022)), .cols =paste0("p[", seq_along(colnames(conteos_2022)), "]"))|>tidyr::pivot_longer(cols =dplyr::starts_with("p"), names_to ="candidato", values_to ="prop")|>dplyr::mutate(cod =stringr::str_remove(candidato,"p_"))|># Nombresdplyr::left_join(candidatos_2022, by ="cod")|>dplyr::filter(cod!="ruido")|>dplyr::group_by(candidato)|>dplyr::mutate(candidato_m =median(prop), .group_by ="drop")|>ggplot2::ggplot(ggplot2::aes(x =prop, y =reorder(nombre, candidato_m)))+ggdist::stat_dist_slabinterval(ggplot2::aes( fill =color_cand, fill_ramp =ggplot2::after_stat(level)), .width =c(0.5, 0.8, 0.95, 0.99), interval_alpha =0.95, show.legend =c(fill =FALSE, fill_ramp =TRUE, size =FALSE))+ggdist::stat_pointinterval(ggplot2::aes(label =scales::percent(candidato_m, accuracy =0.1)), geom ="label", .width =0, vjust =-0.5, size =3, fill ="white", color ="black")+ggplot2::geom_vline(data =.%>%dplyr::distinct(cod, nombre, vuelta_1, color_cand),ggplot2::aes(color =color_cand, xintercept =vuelta_1, label =nombre), linetype ="dashed", show.legend =FALSE)+ggplot2::scale_x_continuous(labels =scales::percent_format(accuracy =1))+ggplot2::scale_fill_identity(na.translate =FALSE)+ggplot2::scale_color_identity(na.translate =FALSE)+ggdist::scale_fill_ramp_discrete( name ="Credible interval", range =c(0.25, 1), breaks =c(0.5, 0.8, .95, 0.99), labels =c("50%", "80%", "95%", "99%"), na.translate =FALSE)+ggplot2::labs( title ="Ajiaco2 cocinado con los ingredientes de la primera vuelta de 2022", subtitle ="Modelo retrospectivo 2022 con base en 32 encuestas", caption ="Fuente: https://recetas-electorales.netlify.app/", x ="% intención de voto estimada", y =NULL)+ggplot2::theme_minimal()+ggplot2::theme( text =ggplot2::element_text(family ="news-cycle", size =20), panel.grid.major.y =ggplot2::element_blank(), panel.grid.minor =ggplot2::element_blank(), legend.position ="top")
Figura 4: Ajiaco2 recalentado con los ingredientes de la primera vuelta de 2022
Receta Ajiaco2
El Ajiaco2 agrega encuestas \(j\) como un vector de conteos por candidato \(y_j\) que se modela como un proceso Dirichlet-Multinomial con un tamaño de muestra \(n_j\), que corresponde a la muestra de cada encuesta.
La lógica del modelo es que existe una distribución de apoyo a los candidatos (las proporciones \(p\)), común a todas las encuestas, y que cada encuesta es una realización ruidosa de esa distribución. Muy similar a los métodos de meta análisis. El parámetro de concentración \(\kappa\) controla qué tan similares son las encuestas entre sí: valores altos implican encuestas muy parecidas y valores bajos permiten mayor variabilidad. El modelo produce no solo estimaciones de apoyo para cada candidato, sino también simulaciones de resultados de encuestas hipotéticas, lo que permite evaluar la incertidumbre y la coherencia del modelo con los datos observados.
Agárrese que el modelo es complicado pero se puede describir, con ayuda de un LLM para el Latex, de la siguiente manera:
Usamos cmdstanr para estimar el modelo luego de transformar las proporciones reportadas en las fichas técnicas de las encuestas en conteos sobre la muestra de cada encuesta. Por ejemplo, si un candidato marcó 20% de la intención de voto en una encuesta de 2 000 personas, el conteo es 400.
Luego la maravilla de compiladores se encargan de estimar el modelo.