Tres tristes errores de las encuestas y cómo se pueden corregir
Autor/a
Afiliación
Recetas Electorales
Análisis independiente
Fecha de publicación
28 de mayo de 2026
Fecha de última modificación
1 de junio de 2026
“Survey weighting is an attempt to use information from the data collection process to make inferences to the target population.” —Andrew Gelman, Red State, Blue State (2008)
La Silla Vacía publicó un artículo donde identificó que Atlas Intel ajusta sus ponderaciones de formas inusuales, de manera que el número de intención de voto de De la Espriella sube antes de cada coyuntura y baja después. La conclusión implícita es que ponderar es una forma sofisticada de amañar una encuesta.
Hay otra lectura del mismo fenómeno, una menos acusatoria, que puede explicar porqué es legítimo que existan ponderaciones tan variables, y de paso nos permite hacer una hipótesis sobre la caja negra de Atlas Intel. En resumidas cuentas, Atlas Intel cuenta con información sobre cómo corregir errores no muestrales que obtiene mediante sus métodos de recolección digital, que permiten identificar sesgos que son invisibles para otros métodos. Eso explicaría sus aciertos y la variabilidad de sus ponderaciones.
El Salpicón muestra, a través de simulaciones, cómo se corrige una encuesta imperfecta utilizando regresión multinivel y post estratificacion (MRP) y cómo se puede corregir los errores más miedosos: Los que no dependen de la muestra.
Los tres tristes errores
Toda encuesta que no sea un muestreo aleatorio estratificado proporcional perfecto suele sufrir de tres tipos de error, cada uno con tratamiento distinto y que se pueden amplificar mutuamente:
Error
Origen
Corrección
Muestral
Composición demográfica desbalanceada
MRP — Ajuste 1
No-respuesta
Los que responden encuestas no representan a todos los votantes
MRP — Ajuste 2
Revelación
Los que responden encuestas no dicen la verdad (shy voter)
Experimento de lista — Ajuste 3
Para ilustrar, asumamos que hay un muestreo aleatorio estratificado proporcional perfecto, donde la muestra replica exactamente la composición del electorado, y veamos cada desviación del ideal.
El ideal: muestreo aleatorio estratificado
En un muestreo aleatorio estratificado (MAE) proporcional, el electorado se divide en grupos y de cada grupo se extrae una muestra cuyo tamaño es proporcional al peso de ese estrato en la población. Si la Costa Caribe es el 22% del electorado, el 22% de las encuestas debe salir de allí. El estimador resultante es insesgado sin necesidad de ningún ajuste posterior.
Ver código
# Muestreo aleatorio estratificado proporcional# La clave: n_h / n = N_h / N para cada estrato hn_total<-1200n_por_region<-round(prop_real*n_total)# asignación proporcionalencuesta_mae<-map2_dfr(regiones, n_por_region, function(region, n){p<-p_real_reg[which(regiones==region)]tibble(region =region, voto_B =rbinom(n, 1, p))})# Con MAE proporcional no hay que ponderar:# la media directa ya es un estimador insesgadotheta_mae<-mean(encuesta_mae$voto_B)
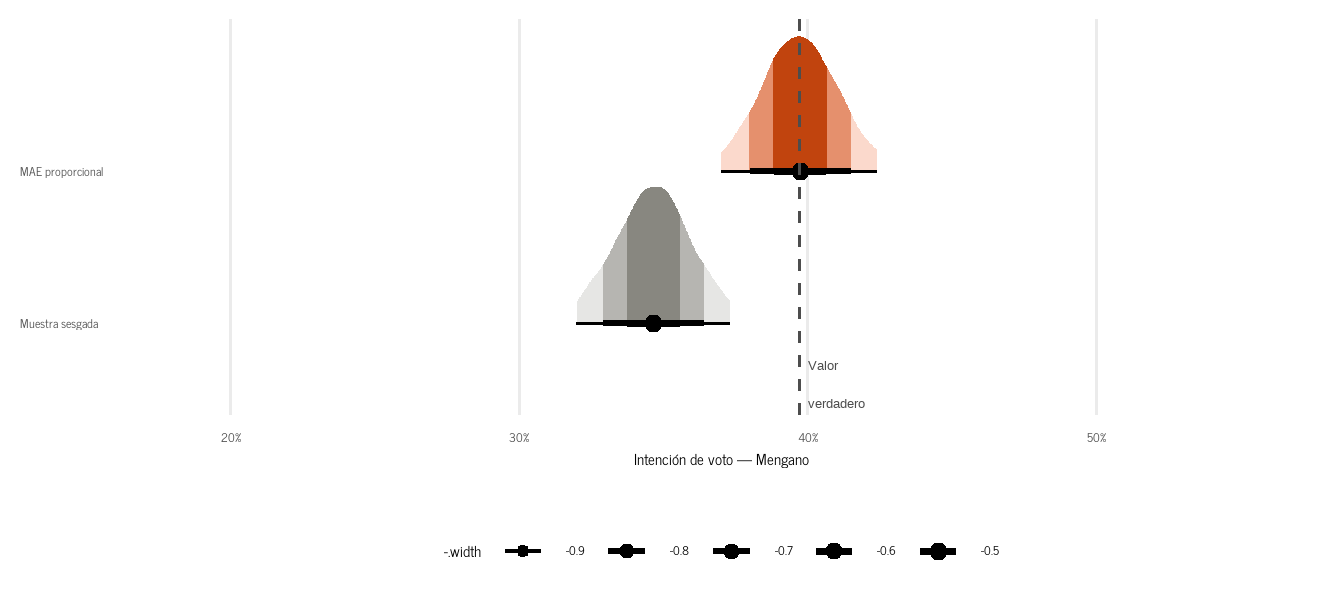
La Figura 1 lo muestra con 5000 encuestas simuladas. Bajo MAE, las estimaciones se distribuyen alrededor del valor verdadero. Con la muestra sesgada —Bogotá sobrerrepresentada, Costa y Resto subrepresentadas— el centro de la distribución cae sistemáticamente por debajo.
Ver código
sims|>mutate(tipo =fct_rev(factor(tipo, levels =c("MAE proporcional", "Muestra sesgada"))))|>ggplot(aes(x =theta, y =tipo, fill =tipo))+ggdist::stat_halfeye(aes(fill_ramp =after_stat(level)), .width =c(0.5, 0.8, 0.95), show.legend =c(fill =FALSE, fill_ramp =FALSE))+geom_vline(xintercept =theta_verdadero, linetype ="dashed", color ="grey30", linewidth =0.7)+annotate("text", x =theta_verdadero+0.003, y =0.6, label ="Valor\nverdadero", hjust =0, size =3.5, color ="grey30")+scale_fill_manual(values =c("MAE proporcional"=col_mae,"Muestra sesgada"=col_cruda))+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0.18, 0.56))+labs(x ="Intención de voto — Mengano", y =NULL)+theme_recetas(base_size =15)+theme(axis.text.y =element_text(hjust =0), panel.grid.major.y =element_blank())
Figura 1: 5000 encuestas simuladas bajo muestreo aleatorio estratificado (MAE) proporcional y bajo muestra sesgada. La línea discontinua marca el valor verdadero de la intención de voto. El MAE es insesgado por construcción; la muestra sesgada no. La tarea de MRP es llevar la encuesta real de vuelta a donde el MAE habría llegado. Datos simulados.
En la práctica, el MAE proporcional es difícil de ejecutar: las encuestas telefónicas y digitales no controlan quién contesta; las cara a cara son lentas y caras. El resultado es casi siempre una muestra desbalanceada. Los dos ajustes que siguen muestran cómo corregirla.
Ajuste 1: Corregir la muestra
MRP recupera lo que el MAE habría dado en dos pasos. Primero, un modelo multinivel aprende la relación entre características demográficas e intención de voto dentro de la muestra sesgada. Segundo, ese modelo se aplica a las celdas del electorado real, ponderadas por su tamaño en la lista oficial de la Registraduría.
El partial pooling hace que los grupos con pocas observaciones —Vaupés, por ejemplo— tomen prestada información estadística de grupos similares en lugar de estimar con ruido puro. Es la misma idea que los efectos de casa en la Cazuela.
Ver código
library(brms); library(tidybayes)fit_mrp<-brm(voto_cand_B~1+(1|region)+(1|estrato)+(1|grupo_edad)+(1|nivel_edu), data =encuesta|>filter(!is.na(voto_cand_B)), family =bernoulli("logit"), prior =c(prior(normal(0, 1.5), class =Intercept),prior(exponential(1), class =sd)), chains =4, iter =2000, warmup =1000, cores =4, seed =42)theta_ajuste1<-lista_votantes|>add_epred_draws(fit_mrp, ndraws =4000)|>group_by(.draw)|>summarise(theta =sum(.epred*n_votantes)/sum(n_votantes))
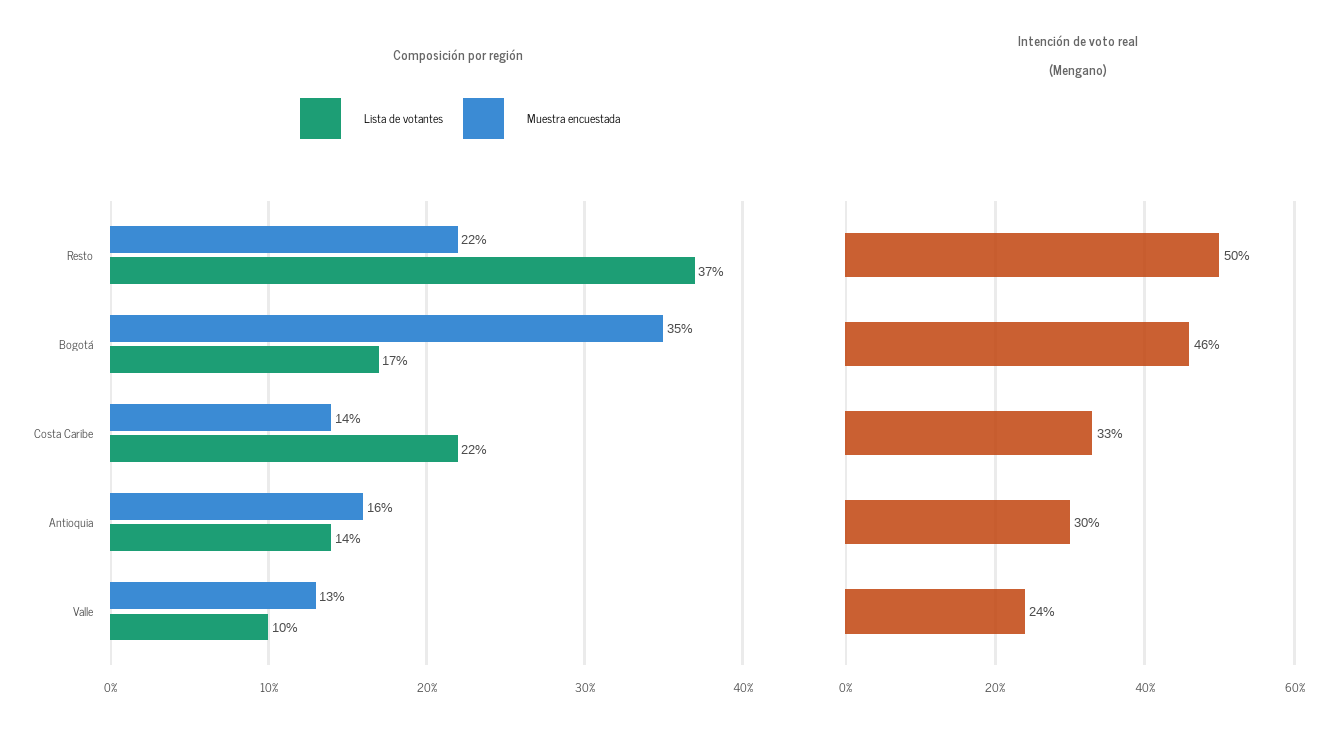
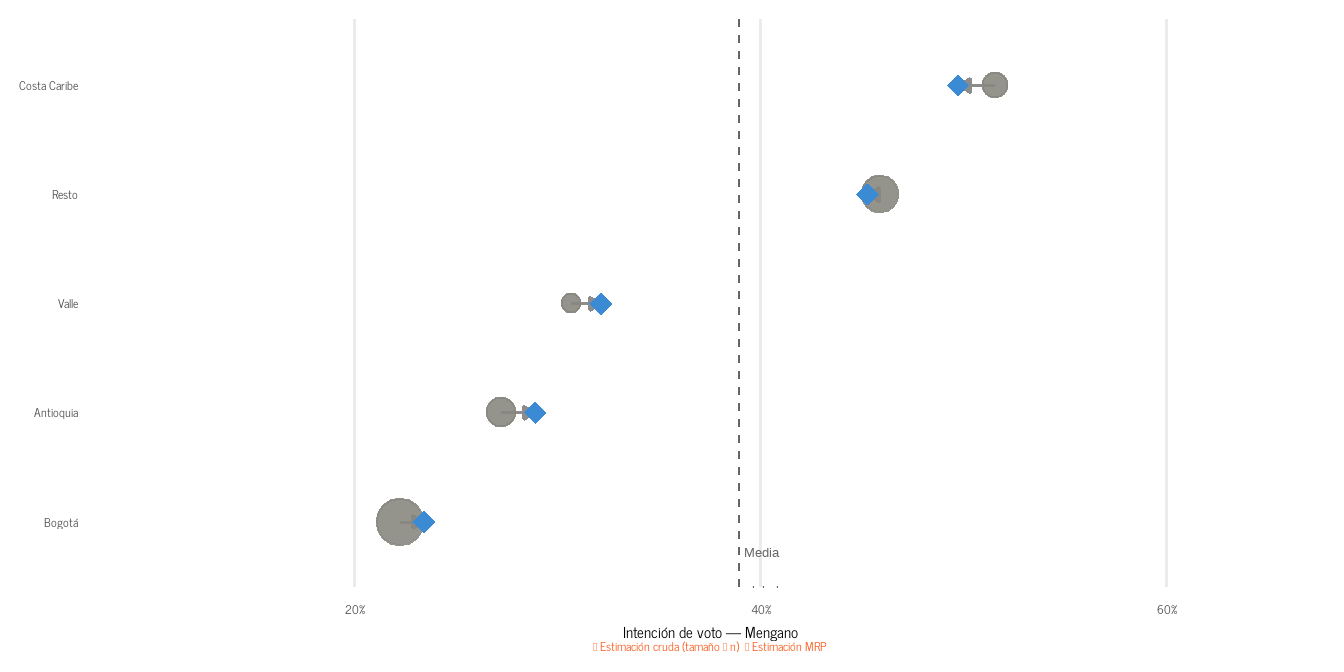
La Figura 2 muestra el origen del sesgo: Bogotá —donde el Mengano es más débil— está sobrerrepresentada al doble de su peso real; la Costa Caribe y el Resto están subrepresentadas. La estimación cruda queda sistemáticamente por debajo del valor verdadero. La Figura 3 muestra el efecto del partial pooling: los grupos pequeños se encogen hacia la media global, los grandes quedan cerca de su estimación directa.
Ver código
p_comp<-bind_rows(tibble(region =regiones, prop =prop_muestra, fuente ="Muestra encuestada"),tibble(region =regiones, prop =prop_real, fuente ="Lista de votantes"))|>mutate(region =fct_reorder(region, prop, .fun =max))|>ggplot(aes(x =prop, y =region, fill =fuente))+geom_col(position =position_dodge(width =0.7), width =0.6)+geom_text(aes(label =scales::percent(prop, accuracy =1)), position =position_dodge(width =0.7), hjust =-0.12, size =3.5, color ="grey30")+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0, 0.44), expand =c(0, 0))+scale_fill_manual(values =c("Muestra encuestada"=col_muestra,"Lista de votantes"=col_real))+labs(x =NULL, y =NULL, fill =NULL, title ="Composición por región")+theme_recetas(base_size =15)+theme(legend.position ="top", panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_voto<-tibble(region =regiones, p =p_real_reg)|>mutate(region =fct_reorder(region, p))|>ggplot(aes(x =p, y =region))+geom_col(fill =col_mae, width =0.5, alpha =0.85)+geom_text(aes(label =scales::percent(p, accuracy =1)), hjust =-0.15, size =3.5, color ="grey30")+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0, 0.62), expand =c(0, 0))+labs(x =NULL, y =NULL, title ="Intención de voto real\n(Mengano)")+theme_recetas(base_size =15)+theme(axis.text.y =element_blank(), panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_comp+p_voto+plot_layout(widths =c(3, 2))
Figura 2: Composición de la muestra vs. lista de votantes por región, y la intención de voto real en cada región. Bogotá —donde el Mengano es más débil— está sobrerrepresentada al doble de su peso real. La Costa Caribe y el Resto —sus bastiones— están subrepresentadas. La estimación cruda queda por debajo de la real. Datos simulados.
Ver código
media_global<-sum(mrp_reg*prop_real)tibble(region =regiones, n_obs =n_reg, cruda =cruda_reg, mrp =mrp_reg)|>mutate(region =fct_reorder(region, cruda))|>ggplot(aes(y =region))+geom_segment(aes(x =cruda, xend =mrp, yend =region), arrow =arrow(length =unit(0.18, "cm"), type ="closed"), color ="grey55", linewidth =0.7)+geom_point(aes(x =cruda, size =n_obs), color =col_cruda, alpha =0.9)+geom_point(aes(x =mrp), color =col_ajuste1, size =3.5, shape =18)+geom_vline(xintercept =media_global, linetype ="dashed", color ="grey40", linewidth =0.5)+annotate("text", x =media_global+0.003, y =0.55, label ="Media\nglobal", hjust =0, size =3.5, color ="grey40")+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0.10, 0.65))+scale_size_continuous(range =c(3, 8), guide ="none")+labs(x ="Intención de voto — Mengano", y =NULL, caption ="● Estimación cruda (tamaño ∝ n) ◆ Estimación MRP")+theme_recetas(base_size =15)+theme(panel.grid.major.y =element_blank())
Figura 3: Partial pooling por región. Los puntos grises son las estimaciones crudas (tamaño ∝ n encuestados); los rombos azules son las estimaciones MRP. Los grupos pequeños se encogen más hacia la media global (línea discontinua). Datos simulados.
Ajuste 2: Corregir quién responde
El Ajuste 1 recupera el balance demográfico pero no ve lo que pasa dentro de cada celda. Incluso si la muestra tuviera exactamente las proporciones correctas por región y estrato, seguiría habiendo un sesgo: dentro de cada celda, los votantes con alto interés político responden más, y no tienen la misma intención de voto que los de bajo interés.
La Encuesta de Cultura Política del DANE tiene diseño probabilístico y pregunta directamente por seguimiento de la política y participación electoral. En su ausencia, la participación histórica municipal de la Registraduría sirve como proxy.
La solución de López-Martín, Phillips y Gelman (2022) es extender la lista de votantes con esa variable usando una encuesta auxiliar representativa, dividir cada celda en dos sub-celdas (interés alto / bajo), e incluir el interés político como predictor en el modelo de voto.
fit_interes<-brm(interes_politico_alto~1+(1|region)+(1|estrato)+(1|grupo_edad), data =encuesta_cultura_politica, family =bernoulli("logit"), prior =c(prior(normal(0, 1.5), class =Intercept),prior(exponential(1), class =sd)), chains =4, iter =2000, warmup =1000, cores =4, seed =42)
fit_mrp_ext<-brm(voto_cand_B~1+(1|region)+(1|estrato)+(1|grupo_edad)+(1|nivel_edu)+interes_politico_alto, data =encuesta|>filter(!is.na(voto_cand_B)), family =bernoulli("logit"), prior =c(prior(normal(0, 1.5), class =Intercept),prior(normal(0, 1), class =b),prior(exponential(1), class =sd)), chains =4, iter =2000, warmup =1000, cores =4, seed =42)theta_ajuste2<-lista_extendida|>add_epred_draws(fit_mrp_ext, ndraws =4000)|>group_by(.draw)|>summarise(theta =sum(.epred*n_votantes_ext)/sum(n_votantes_ext))
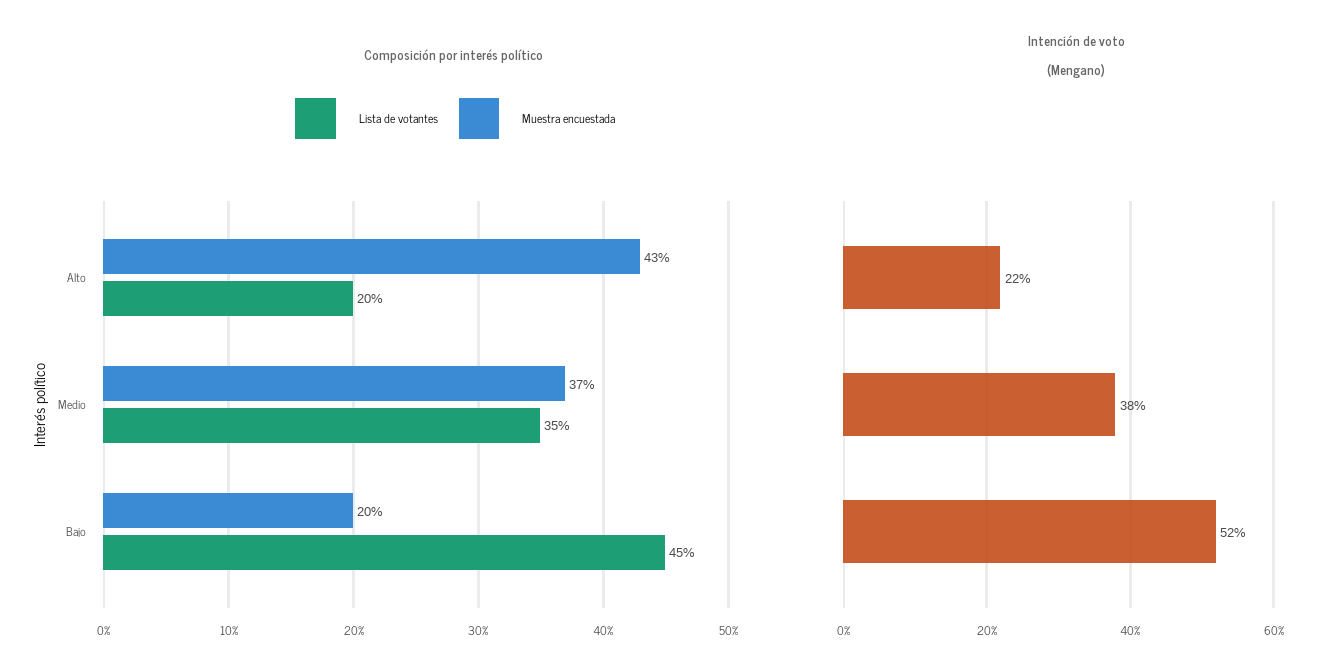
La Figura 4 muestra la mecánica del sesgo de no-respuesta para el Mengano. Sus simpatizantes típicos —bajo interés político declarado— son los que menos responden encuestas. Es el perfil clásico del electorado populista: desenganchado de la política formal, invisible para los métodos de recolección convencionales.
Ver código
p_comp2<-no_respuesta|>pivot_longer(c(prop_electorado, prop_muestra), names_to ="fuente", values_to ="prop")|>mutate(interes =factor(interes, levels =c("Bajo", "Medio", "Alto")), fuente =recode(fuente, prop_electorado ="Lista de votantes", prop_muestra ="Muestra encuestada"))|>ggplot(aes(x =prop, y =interes, fill =fuente))+geom_col(position =position_dodge(width =0.65), width =0.55)+geom_text(aes(label =scales::percent(prop, accuracy =1)), position =position_dodge(width =0.65), hjust =-0.12, size =3.5, color ="grey30")+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0, 0.56), expand =c(0, 0))+scale_fill_manual(values =c("Muestra encuestada"=col_muestra,"Lista de votantes"=col_real))+labs(x =NULL, y ="Interés político", fill =NULL, title ="Composición por interés político")+theme_recetas(base_size =15)+theme(legend.position ="top", panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_voto2<-no_respuesta|>mutate(interes =factor(interes, levels =c("Bajo", "Medio", "Alto")))|>ggplot(aes(x =p_voto, y =interes))+geom_col(fill =col_mae, width =0.5, alpha =0.85)+geom_text(aes(label =scales::percent(p_voto, accuracy =1)), hjust =-0.15, size =3.5, color ="grey30")+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0, 0.65), expand =c(0, 0))+labs(x =NULL, y =NULL, title ="Intención de voto\n(Mengano)")+theme_recetas(base_size =15)+theme(axis.text.y =element_blank(), panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_comp2+p_voto2+plot_layout(widths =c(3, 2))
Figura 4: El doble sesgo de la no-respuesta diferencial. El grupo de bajo interés político está subrepresentado en la muestra y a la vez es el más afín al Mengano. Su ausencia hace que incluso el Ajuste 1 todavía subestime el apoyo real. Datos simulados.
Ajuste 3: Corregir lo que el elector no revela
El votante tímido (shy voter) es el elector que sabe cuál es la respuesta socialmente aceptable y la da, aunque no refleje su intención real. A diferencia de los dos errores anteriores, no deja huella en los datos: El encuestado parece cooperativo, contesta, y su respuesta se registra como válida. En Colombia, el efecto puede operar en cualquier dirección. La respuesta “vergonzosa” depende del contexto social del encuestado, o de un candidato en sí. Por ejemplo, votantes con preferencias politicas conservadoras que no votarían por una mujer para presidente.
Los Ajustes 1 y 2 no corrigen este problema porque actúan sobre la composición de la muestra, no sobre la veracidad de las respuestas. Un MRP perfecto post-estratificado sobre el padrón real seguirá subestimando si los simpatizantes del Mengano declaran apoyar a alguien más.
La familia de técnicas que aborda este problema se llama elicitación indirecta. La más validada empíricamente es el experimento de lista (item count technique; Blair e Imai, 2012).
TipCómo funciona el experimento de lista
La muestra se divide al azar en dos grupos:
Control: recibe \(N\) afirmaciones no sensibles y solo reporta cuántas son verdaderas para él.
Tratamiento: recibe las mismas \(N\) afirmaciones más el ítem sensible y también solo reporta el conteo.
Como nadie admite directamente el ítem sensible, el sesgo de deseabilidad social desaparece por diseño. El costo es varianza: con el mismo \(n\), el estimador es \(\approx \sqrt{2}\) veces menos preciso que una pregunta directa.
Ver código
# Grupo control: solo ítems no sensiblesctrl_l<-rowSums(sapply(p_neu, function(p)rbinom(n_ctrl, 1, p)))# Grupo tratamiento: ítems no sensibles + ítem sensibletrat_l<-rowSums(sapply(p_neu, function(p)rbinom(n_trat, 1, p)))+rbinom(n_trat, 1, p_real)# voto real, no declaradop_lista_est<-mean(trat_l)-mean(ctrl_l)
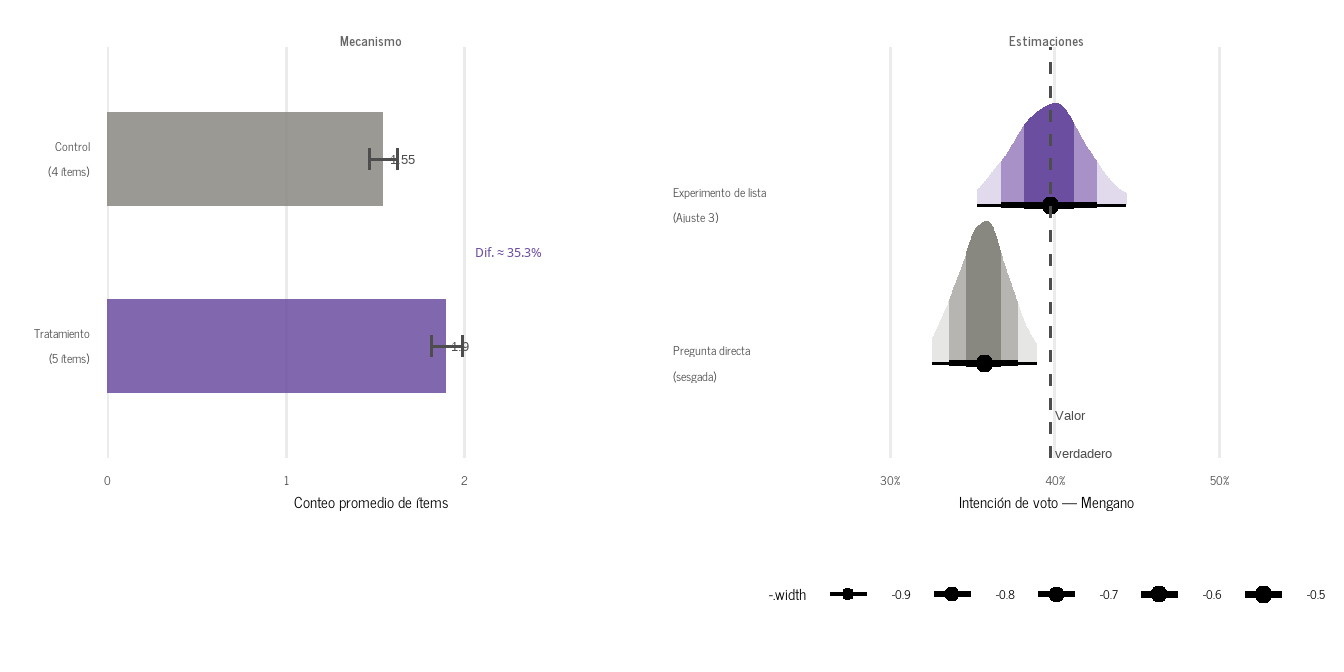
La Figura 5 ilustra el mecanismo con datos simulados donde el sesgo de deseabilidad es de 4 puntos porcentuales: la pregunta directa da 36%, cuatro puntos por debajo del valor real (40%). El experimento de lista recupera una estimación centrada en el valor verdadero, a expensas de mayor varianza.
Ver código
p_left<-tibble( grupo =factor(c("Control\n(4 ítems)", "Tratamiento\n(5 ítems)"), levels =c("Tratamiento\n(5 ítems)", "Control\n(4 ítems)")), media =c(mean(ctrl_l), mean(trat_l)), se =c(sd(ctrl_l)/sqrt(n_lista_ctrl),sd(trat_l)/sqrt(n_lista_trat)))|>ggplot(aes(x =media, y =grupo, fill =grupo))+geom_col(width =0.5, alpha =0.85)+geom_errorbar(aes(xmin =media-1.96*se, xmax =media+1.96*se), width =0.12, color ="grey30")+geom_text(aes(label =round(media, 2)), hjust =-0.25, size =3.5, color ="grey30")+annotate("text", x =mean(trat_l)+0.35, y =1.5, label =paste0("Dif. ≈ ",scales::percent(mean(trat_l)-mean(ctrl_l), accuracy =0.1)), size =3.5, color =col_ajuste3, hjust =0.5)+scale_x_continuous(limits =c(0, max(mean(trat_l))*1.55), expand =c(0, 0))+scale_fill_manual(values =c("Control\n(4 ítems)"=col_cruda,"Tratamiento\n(5 ítems)"=col_ajuste3), guide ="none")+labs(x ="Conteo promedio de ítems", y =NULL, title ="Mecanismo")+theme_recetas(base_size =15)+theme(panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_right<-bind_rows(tibble(theta =post_directa, tipo ="Pregunta directa\n(sesgada)"),tibble(theta =post_ajuste3, tipo ="Experimento de lista\n(Ajuste 3)"))|>mutate(tipo =fct_inorder(tipo))|>ggplot(aes(x =theta, y =tipo, fill =tipo))+ggdist::stat_halfeye(aes(fill_ramp =after_stat(level)), .width =c(0.5, 0.8, 0.95), show.legend =c(fill =FALSE, fill_ramp =FALSE))+geom_vline(xintercept =theta_verdadero, linetype ="dashed", color ="grey30", linewidth =0.6)+annotate("text", x =theta_verdadero+0.003, y =0.55, label ="Valor\nverdadero", hjust =0, size =3.5, color ="grey30")+scale_fill_manual(values =c("Pregunta directa\n(sesgada)"=col_cruda,"Experimento de lista\n(Ajuste 3)"=col_ajuste3))+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0.25, 0.54))+labs(x ="Intención de voto — Mengano", y =NULL, title ="Estimaciones")+theme_recetas(base_size =15)+theme(axis.text.y =element_text(hjust =0), panel.grid.major.y =element_blank(), plot.title =element_text(size =10, color ="grey40"))p_left+p_right
Figura 5: Experimento de lista versus pregunta directa. Panel izquierdo: conteo promedio de ítems por grupo; la diferencia entre tratamiento y control identifica la prevalencia del ítem sensible sin que nadie lo admita explícitamente. Panel derecho: distribución del estimador de lista frente a la pregunta directa y al valor verdadero. Datos simulados.
Resultado
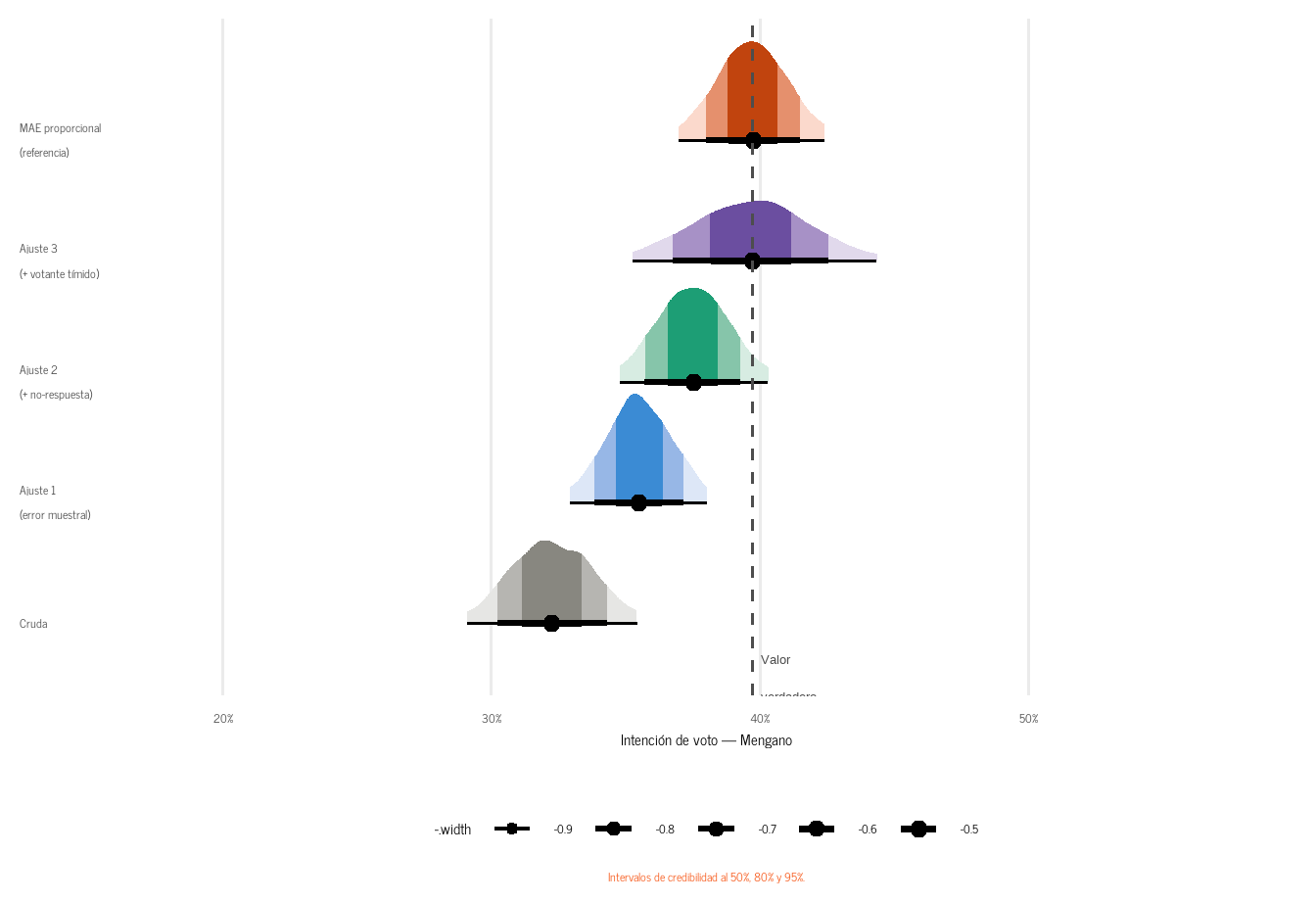
La Figura 6 muestra la progresión completa de los tres ajustes. La estimación cruda subestima al Mengano porque la muestra ignora sistemáticamente sus bastiones geográficos, su electorado menos politizado, y el sesgo de deseabilidad social. Cada ajuste recupera una parte del error: el Ajuste 1 corrige la composición demográfica; el Ajuste 2 suma la no-respuesta diferencial; el Ajuste 3 (experimento de lista) recupera los votos que nadie quería admitir. El MAE sirve como referencia final.
Ver código
mae_media<-sims|>filter(tipo=="MAE proporcional")|>pull(theta)bind_rows(tibble(theta =post_cruda, tipo ="Cruda"),tibble(theta =post_ajuste1, tipo ="Ajuste 1\n(error muestral)"),tibble(theta =post_ajuste2, tipo ="Ajuste 2\n(+ no-respuesta)"),tibble(theta =post_ajuste3, tipo ="Ajuste 3\n(+ votante tímido)"),tibble(theta =mae_media, tipo ="MAE proporcional\n(referencia)"))|>mutate(tipo =fct_inorder(tipo))|>ggplot(aes(x =theta, y =tipo, fill =tipo))+ggdist::stat_halfeye(aes(fill_ramp =after_stat(level)), .width =c(0.5, 0.8, 0.95), show.legend =c(fill =FALSE, fill_ramp =FALSE))+geom_vline(xintercept =theta_verdadero, linetype ="dashed", color ="grey30", linewidth =0.6)+annotate("text", x =theta_verdadero+0.003, y =0.55, label ="Valor\nverdadero", hjust =0, size =3.5, color ="grey30")+scale_fill_manual(values =c("Cruda"=col_cruda,"Ajuste 1\n(error muestral)"=col_ajuste1,"Ajuste 2\n(+ no-respuesta)"=col_ajuste2,"Ajuste 3\n(+ votante tímido)"=col_ajuste3,"MAE proporcional\n(referencia)"=col_mae))+scale_x_continuous(labels =scales::percent_format(accuracy =1), limits =c(0.18, 0.58))+labs(x ="Intención de voto — Mengano", y =NULL, caption ="Intervalos de credibilidad al 50%, 80% y 95%.")+theme_recetas(base_size =15)+theme(axis.text.y =element_text(hjust =0), panel.grid.major.y =element_blank())
Figura 6: Progresión de las cinco estimaciones. Cada corrección acerca la distribución al valor verdadero. El experimento de lista (Ajuste 3) cierra la brecha residual que MRP no puede ver: lo que el elector no dijo. Datos simulados.
En defensa de Atlas Intel
Volvamos al comienzo. La Silla Vacía reportó que Atlas Intel sube el número de De la Espriella antes de cada coyuntura y lo baja después. El tono del artículo sugería que esos cambios son evidencia de manipulación deliberada. Pero hay una explicación más parsimoniosa, más consistente con su trayectoria pronosticadora: que los ajustes son metodología correcta respaldada por información que la compañía no ha publicado.
¿Por qué? Porque las tres correcciones que acabamos de ver no son opcionales si el objetivo es pronosticar. Una encuesta online sobrerrepresenta a los usuarios activos de la plataforma: más urbanos, más jóvenes, más educados. Si la base de registro de Atlas Intel cambia entre coyunturas por nuevos usuarios, diferente tasa de respuesta por región, etc, los pesos correctos también deberían cambiar. Que los números se muevan no es evidencia de manipulación: es evidencia de que el modelo de ponderación es sensible a los datos, que es exactamente lo que debe ser.
Además, dado que Atlas Intel opera en formato digital, esto les permite hacer algo que las encuestas cara a cara y telefónicas no pueden a escala: experimentos de lista. Con cientos de miles de panelistas activos, dividir aleatoriamente la muestra en grupos de control y tratamiento no tiene costo marginal. Si Atlas Intel está realizando este tipo de experimentos para medir el sesgo del votante tímido, y si les están saliendo bien, esa es exactamente la salsa secreta dentro de la caja negra. No hay manipulación maquiavélica, solo una metodología avanzada de la que deberían presumir, pero no se puede revelar porque sería fácil de copiar.
Así que la caja negra, la salsa secreta, parece ser la corrección dinámica de sesgos muestrales y no muestrales, y es posible gracias a los métodos que se pueden implementar con instrumentos digitales.
Resultado — primera vuelta 31 de mayo de 2026
NotaResultados oficiales
Candidato
% Votos válidos
Abelardo de la Espriella
43.72%
Iván Cepeda
40.92%
Paloma Valencia
6.92%
Sergio Fajardo
4.26%
Claudia López
0.95%
El resultado confirma el análisis del Salpicón: los errores sistemáticos fueron grandes — ADLE subestimado en más de 15 p.p., Paloma sobreestimada en más de 13 p.p. AtlasIntel fue la encuestadora que más se acercó al resultado de ADLE (36.3% vs 43.72%), lo que es consistente con su corrección dinámica de sesgos descrita en este artículo. El análisis detallado de desempeño de encuestadoras está en Café.
Referencias
Cómo citar
BibTeX
@online{recetas_electorales2026,
author = {{Recetas Electorales}},
title = {🫙 Salpicón},
date = {2026-05-28},
url = {https://www.recetas-electorales.com/elecciones/2026-colombia/2026-05-28-salpicon/2026-salpicon.html},
langid = {es}
}